
호다닥 톺아보는 데이터저장소 친구들(feat. DB,DW,DL,LH)
Overview
대충 개념정도만 알고 있었던 Database, Data Warehouse, Data Lake, Data Lakehouse….
최근 접할 일이 많아져서 이참에 개념들을 쭉 정리해보고자 합니다.
DataBase
Concept
IT관련 일을 한다면 모를수가 없는 용어죠, 데이터 저장소입니다.
- DBMS(Database Management System)을 통해 관리&운영
- ex)
MySQL,PostgreSQL,Oracle,Db2 - 관계형 데이터베이스(RDBMS)에서는 table이라는 단위로 데이터가 저장되며 table은 row, column으로 구성

Transaction
그래서 이 DB를 가지고 무엇을 할까요?

쇼핑몰이라면 유저의 정보가 담긴 DB, 상품의 정보, 주문 정보, 가게 정보 등등이 담긴 DB들이 있을 것이고,
사용자가 주문하게 되면 DB에 쿼리를 날려서 정보를 읽고 쓰고 하게될 것입니다.
이렇게 데이터베이스의 상태를 변환시키는, 하나의 논리적 기능을 수행하기 위한 작업의 단위,
혹은 한꺼번에 수행되어야 할 일련의 연산들을 트랜잭션(Transaction) 이라고 합니다.
ACID
이 트랜잭션이 안전하게 수행된다는 것을 보장하기 위해 나온 개념으로, ACID라는 것이 있습니다.
- 원자성(Atomicity)
- 트랜잭션의 연산은 DB에 모두 반영되던지, 아님 전혀 반영되지 않아야 함
- 트랜잭션 내의 모든 명령은 반드시 수행되어야하며, 한 단계라도 오류가 발생되면 트랜잭션 전부 취소해야함
- 일관성(Consistency)
- 작업이 실패하더라도 실패한 상태의 데이터를 방치하지 않음
- 데이터의 일관성 유지
- 격리성(Isolation)
- 트랜잭션이 실행 중인 경우 다른 트랜잭션에 의해 데이터가 변경되는것을 방지
- 지속성(Durability)
- 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나도 영구적으로 반영되어야함
OLTP
그래서 DB는 트랜잭션 지향 어플리케이션을 손쉽게 관리할 수 있도록 도와주는 OLTP(OnLine Transaction Processing) 에 특화되어 있습니다.
- 일반적인 데이터 기입 및 트랜잭션 처리
- 한번에 수천명의 사용자 처리 가능,
- CRUD작업을 빠르게 수행할 수 있도록 최적화
- 운영 목적으로 트랜잭션 데이터를 관리하고 처리하는데 사용됨
데이터 분석 관점으로서의 DB
그러나 데이터 분석 영역으로 들어오게 되면, 데이터를 삽입, 수정, 삭제하는 작업 대신
특정 필드 데이터 집합을 조회하는 경우가 많아지게 됩니다.

예를 들어, 주문하는 사람들의 나이의 통계를 내고 싶다던지, 연령대별 구매 품목의 경향성을 분석하는 상황을 생각해볼 수 있겠습니다.
이런 경우엔 row 전체의 정보가 필요하다기보다는 특정 column의 데이터만 필요한 경우가 많습니다.
그래서 분석과 질의응답에 최적화된 OLAP(OnLine Analytical Processing) 시스템이라는 개념이 새로 생기게 됩니다.
한번 전국의 매장 실적을 더 잘 이해하고자 하는 대형 리테일 기업을 상상해봅시다!
제품, 날짜, 위치에 대한 정보를 포함해서, 모든 매장에서 매일 판매되는 데이터를 수집할 것입니다.
다차원 분석 : 이 데이터들을 모아서 지역별, 제품별, 기간별 등 다양한 각도에서 데이터를 분석해볼 수 있을것이고
데이터 집계 : 로우데이터들을 집계하여 월별/연도별 총 판매량과 같은 주요 정보를 얻을 수도 있고
드릴다운 : 특정 지역의 특정 제품 판매실적과 같은 구체적인 세부 정보까지 드릴다운하여 원하는 정보를 얻을 수도 있을 것입니다.
이처럼 최종 사용자가 다차원 정보에 직접 접근하여 분석하고 의사결정에 활용화는 과정을 OLAP라고 합니다.
그러나 이런 OLAP시스템을 DB로만 구성하기엔 복잡한 SQL을 사용해야하고, SQL특성상 잘못된 쿼리를 날리게되면 돌이킬 수 없을수도 있었기 때문에
2001년 Data warehouse라는 개념이 처음 등장하게 됩니다.
(OLAP는 1993년 에드커F커드에 의해 제안)
Data Warehouse
Concept

데이터 웨어하우스란 사용자의 의사결정에 도움을 주기 위해 DB에 축적된 데이터를 공통의 형식으로 변환해 관리하는 데이터베이스를 일컫는 시스템입니다.
- 기업 전체에 대한 BI(Business Intelligence) 및 분석을 지원
- 여러 소스의 데이터를 일관된 중앙집중식 데이터 저장소로 집계
- 데이터 분석, 데이터마이닝, 인공지능 등에 활용 가능
그리고 다음과 같은 특징을 지니고 있습니다.
-
주제 지향(Subject Oriented)
기존의 DB가 ‘기능’이나 ‘업무’처리를 중심으로 설계되는 것에 비해 DW는 고객, 거래처, 공급자, 상품 등과 같은 ‘주제’중심으로 구성된다. -
통합(Integrated)
데이터 웨어하우스는 신뢰할 수 있는 하나의 버전(One version of truth)을 사용자에게 제공, 기존 운영시스템 같은 경우 많은 부분들이 중복되어서 한가지 사실에 대한 다수의 버전이 존재하지만 데이터 웨어하우스는 데이터를 일관적인 형태로 변환해 저장함으로써 전사적인 관점에서 데이터를 통합시킴 -
시계열성(Time Varient)
데이터 웨어하우스에 있는 데이터는 일정 기간동안의 정확성을 보증함 일정한 시간 동안의 데이터를 대변하는 것으로 snapshot과 같다고 할 수 있다. 따라서 데이터 구조상에 ‘시간’이 아주 중요한 요소로 작용 -
비휘발성(Nonvolatile)
일단 데이터가 DW에 적재되면 일괄 처리(batch)작업에 의한 갱신 이외에는 Insert나 Delete등의 변경이 수행되지 않음
즉 읽기 전용 데이터베이스
ETL 혹은 ELT
결국 데이터 웨어하우스는 데이터를 어떻게 잘 모아서, 주제별로 예쁘게 쌓아 유저에게 보여줄 수 있을까가 목적입니다.
그럼 데이터 수집 및 처리에 해당되는 과정인 ETL에 대해서 먼저 알아보겠습니다.

Extract : 하나 또는 그 이상의 데이터 소스로부터 데이터를 추출
Transform : 추출한 데이터를 요구사항에 맞게 변경 (필터링, 정렬, 집계, 데이터 조인, 정리, 중복제거, 데이터 유효성 검사 등)
Load : 데이터를 특정 목표 시스템에 적재
ELT같은 경우는 먼저 원래 형식으로 데이터를 로드 -> 웨어하우스에서 처리하면서 데이터를 정리하고 구조화하는 순서로 이뤄지게 됩니다.
일반적으로 전사적인 데이터 정리나 규칙준수를 위해 중앙집중식으로 데이터를 처리가 필요할 경우 사용된다고 보시면 됩니다.
Data Mart
데이터마트는 특정 LOB(Line of Business), 부서, 주제 영역에 중점을 둔 데이터 웨어하우스의 하위 개념으로, 사용자는 전체 DW를 검색하지 않고도 중요한 인사이트를 신속하게 얻을 수 있게 해줍니다.
데이터 웨어하우스가 여러 소스의 데이터를 중앙의 일관된 단일 데이터 저장소로 집계해 하나의 통합된 형식으로 제공하는 반면,
데이터마트는 조직 내 단일팀 또는 일부 사용자그룹에 필요한 소규모 하위 데이터를 담고 있다고 보시면 됩니다.
예를 들어서 마케팅 팀에서 AI행사를 위한 행사를 기획한다고 했을 때 고객 정보와 같은 필요한 데이터만 데이터 마트로 만들어서 제공한다면
모든 엔터프라이즈 데이터에 액세스할 필요 없이 더 빨리 인사이트를 얻을 수 있을 것입니다.
OLAP
이제 여기서 위에 짧게 설명한 OLAP(OnLine Analytical Processing) 의 개념을 실현할 수 있게됩니다.
- 다차원 분석
- 최종 사용자가 다차원으로 이루어진 데이터로부터 통계 정보를 분석해 의사결정에 활용하는 방식
- DW와 DM과 같은 시스템과 상호 연관되는 시스템
- DW가 데이터를 저장하고 관리한다면 OLAP는 데이터웨어하우스의 데이터를 전략적인 정보로 변환
솔루션으로는 Cognos, Power BI등이 있습니다.
점점 쌓여가는 여러 형식의 데이터들
기본적으로 데이터 웨어하우스는 명확하게 구조화된 정형데이터만 저장하고 처리할 수 있습니다.
그러나 Gartner에서는 조직 내 데이터의 최대 80%가 비정형 데이터라고 추정하고 있을만큼
이미지, 텍스트, IoT데이터 등의 비정형데이터들은 기하급수적으로 늘어나고 있습니다.
이런 비정형 데이터들의 저장소로 DW는 값비싸고 적절하지 않습니다.
그리고 정형데이터들이라 하더라도, 이것을 DW에 적재하기 위해선 “시간”이 필요했으며, 이렇게 모아둔 데이터들 모두가 유용한 가치를 지니고 있다고 보기도 어려웠습니다.
또한 DW는 일반적으로 SQL만 지원하고 R이나 Python같은 데이터 엔지니어들이 자주 사용하는 언어를 지원하지 않기 때문에 AI/ML 워크로드에서 사용하기가 쉽지 않았죠.
그래서 “DataLake” 라는 개념이 새롭게 탄생하게 됩니다.
Data Lake
Concept

이름 그대로 데이터의 호수입니다.
모든 형식의 데이터를 한 곳에 저장시키는 것이 Data Lake의 목적입니다.
- 비정형데이터를 포함한 모든 형식의 데이터 저장 가능
- 가공되지 않은 형태인 RAW데이터가 저장됨
- 주로 Object Storage를 사용하여 대규모 데이터들을 저장하기때문에 비용 효과적으로 운영 가능
- SQL, Python, R등의 언어와 서드파티 애플리케이션을 사용해 데이터 분석 가능
- AI/ML 워크로드에 사용가능
Data Warehouse와 Data Lake의 차이점
데이터를 한 곳에 저장하는 대규모 저장소로써는 둘이 비슷하게 여겨질 수 있지만, 각자 다른 용도로 사용되어집니다.
저장되는 데이터의 관점에서 본다면:
Data Warehouse는 데이터를 저장하기 이전에 형태와 구조를 결정하여 저장, 이를 Schema on write라고 합니다Data Lake는 원시데이터를 그대로 저장하고 데이터를 읽을 때 데이터에 형태와 구조를 결정, 이를 Schema on Lead라고 합니다.
저장되는 데이터의 목적 또한:
Data Warehouse는 명확한 목적이 존재하는 데이터들이 저장됩니다Data Lake는 목적없이 모든 데이터가 저장됩니다
데이터를 저장하는 속도는:
Data Warehouse는 저장하기 이전에 데이터를 정제해야하는데 시간이 오래소요됨Data Lake는 즉시 데이터를 수집하여 바로 저장가능(실시간 데이터)
데이터가 저장되는 장소:
Data Warehouse같은 경우 고비용의 스토리지를 사용해야 하지만Data Lake는 오브젝트 스토리지 혹은 HDFS를 사용하여 상대적으로 저렴한 비용으로 확장성있는 구성을 할 수 있음
활용되는 곳:
Data Warehouse는 주제 중심으로 모은 구조화된 데이터들을 통해 BI, 데이터 분석 및 마이닝에 활용Data Lake는 대량의 RAW데이터들을 통해 다양한 유형의 사용자가 다양한 요구사항들을 충족할 수 있음, ML, 예측 분석, 실시간 분석등 다양한 작업에 활용
여러 차이점들이 존재하지만, 이 둘은 양자택일 해야하는 도구가 아닌 상호보완적인 관계입니다.
DataLake에 저장된 원시 데이터는 비즈니스 질문에 대답하기 위해 필요하며, 향후 분석을 위해 Data Warehouse에서 추출, 정리, 변환하여 사용할 수 있습니다.
DataLake의 한계점
저비용의 스토리지에! 모든 유형의 데이터를 넣어서 관리할 수 있다니!
이보다 좋은 것이 없을 것 같지만 이런 DataLake에도 한계점은 존재합니다.

-
데이터 늪 (Data Swamp)
여러 유형의 원시데이터가 저장되는 만큼, 효과적인 분류 및 변환 없이 너무 많은 데이터가 저장되게 되면 필요한 데이터를 찾기 어렵고 신뢰성도 떨어지게됩니다.
이렇게 데이터의 품질과 거버넌스가 미흡하여 유용한 인사이트를 제공하기 어려운 상태를 “데이터 늪”이라고 합니다. -
느린 성능
DataLake는 대규모로 운영되도록 설계되었지만 저장된 데이터의 규모가 커질수록 전통 쿼리엔진 성능이 저하됩니다.
그래서 DataLake의 장점을 유지하면서, 데이터 관리와 분석이 어렵다는 단점을 보완한 새로운 아키텍처가 떠오르게 됩니다!
Data Lakehouse
concept
결국 지난 세월동안 데이터에 대한 기업들의 본질적인 요구는 크게 변하지 않았습니다.
다양한 데이터를 통합해 분석하여 유용한 인사이트를 찾아내고,
기하급수적으로 생성되는 여러 방대한 데이터들을 잘 모아두는 것입니다.
대다수 기업들은 그를 위해서, 목적에 맞게 구축된 여러 Data Warehouse와, 모든 데이터들을 빠르게 수집할 수 있는 Data Lake를 동시에 운영하고 있었습니다.
그러나 두 계층으로 분리된 데이터 아키텍처는 복잡성이 증가하고, 데이터 분석을 위해 Data Lake에서 Data Warehouse로 데이터를 옮기게 되면 데이터를 이중으로 저장하게되며, 비용과 관리 문제가 지속적으로 발생하게 됩니다.
그럼 그 두개의 아키텍처를 합치면 어떨까요?
그래서 고성능의 데이터 관리와 구조화 기능의 데이터웨어하우스와, 유연하고 저렴한 스토리지의 데이터레이크의 장점만을 합친 아키텍처가 등장하게 됩니다!
바로 Data Lakehouse 입니다.
- 다양한 데이터의 형태(정형, 반정형, 비정형)를 수집&저장
- Business Intelligence, Data Science 워크로드
- 데이터 관리 기능을 통해 스키마 적용, 데이터 거버넌스, ETL 및 데이터 정리기능 제공
- ACID속성 제공을 통해 여러 사용자의 데이터 동시 읽기 및 쓰기 보장
- 컴퓨팅 및 스토리지 리소스 분리를 통해 다양한 워크로드 확장
- BI앱이 직접 데이터 소스에 액세스함으로써 데이터 중복 축소
Architecture
크게 다섯가지 레이어로 구성됩니다.
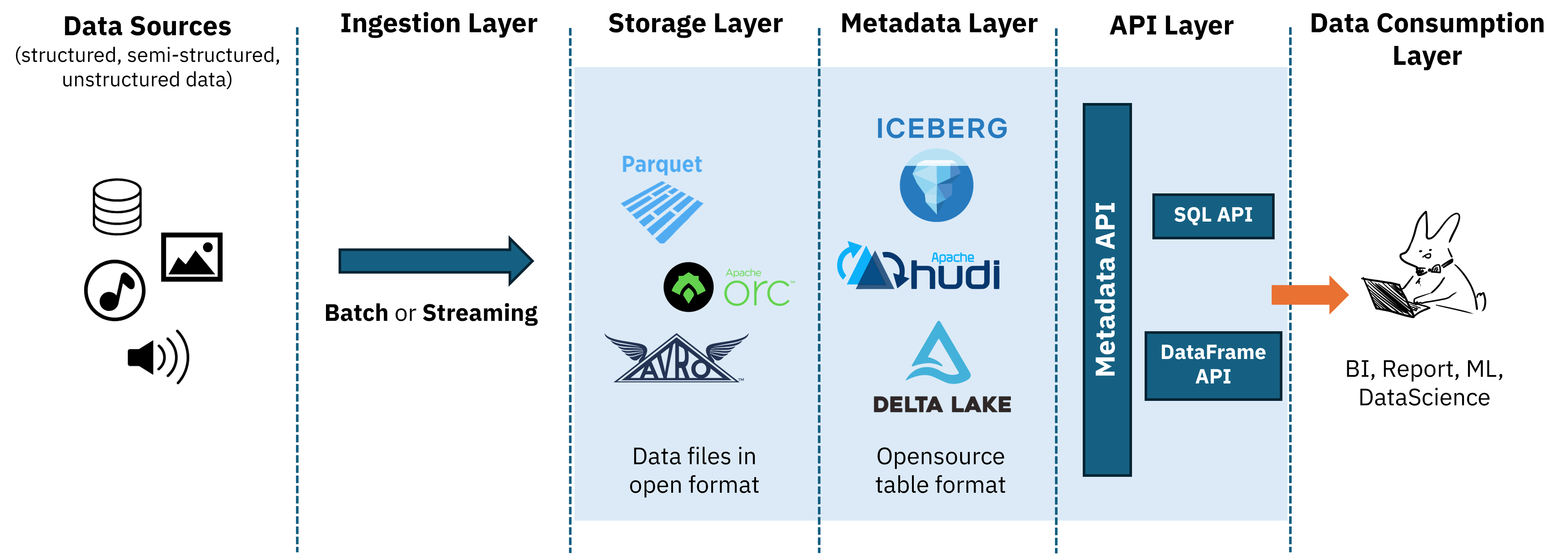
1. Ingestion Layer
여러 다양한 소스(DB, NoSQL DB, social media등) 에서 데이터를 수집하여 레이크하우스에 저장하고 분석할 수 있는 형식으로 변환하는 단계입니다.
데이터를 수집하는 방식은 크게 두가지가 있습니다.
Batch Processing:
특정 시간 범위 내에서 대량의 데이터를 일괄적으로 처리하는 방식을 일컫습니다.
데이터 크기가 고정되어있고 유한할 경우 사용되는 방식이며,
일정 시간마다 쌓인 데이터들을 처리하기 때문에 실시간 데이터를 필요로 하는 경우에는 알맞지 않은 방식입니다.
Stream Processing
데이터가 생성되는 즉시 처리되는 방식을 일컫습니다.
소스 데이터의 크기를 알 수 없고, 무한하고 연속적일 경우 사용되며,
데이터가 생성되는 즉시 처리되기 때문에 실시간 분석이 필요한 워크로드에 사용됩니다.
2. Storage Layer
모든 RAW데이터를 Parquet또는 ORC와 같은 여러 오픈 포맷으로 저장 가능, 주로 오브젝트 스토리지 혹은 HDFS로 구성됩니다.
컴퓨팅 리소스와 분리되어있으므로 독립적인 확장이 가능합니다.
3. Metadata Layer
스토리지의 모든 객체에 대한 메타데이터를 제공하는 통합 카탈로그.
레이크하우스 아키텍처의 핵심이며, 이 단계때문에 ACID, Upsert, TimeTravel등과 같은 기능을 사용할 수 있게 됩니다.
테이블에 생성,수정,삭제작업이 발생할 때마다 메타데이터파일이 새롭게 생기게되고, 시스템은 최신 메타데이터로의 포인터를 통해 데이터의 최신성을 유지합니다.
각 변경점마다 메타데이터가 생성되기 때문에, MVCC(Multi Version Concurrency Content)를 통해 동시성 제어가 가능해지고, 이를 통해 ACID를 가능하게 합니다.
또한 각 버전별 메타데이터를 테이블 스냅샷으로 여겨 과거 데이터에의 쿼리(Time Travel)나, 과거 데이터로의 롤백(Rollback)도 가능하게 합니다.
MVCC(Multi Version Concurrency Content)?
원본 데이터와 변경중인 데이터를 동시에 유지하는 방식
하나의 레코드에 여러 버전이 관리되며 이를 통해 lock방식을 사용하지 않고 일관된 데이터 동시접근을 허용합니다.
4. API Layer
API제공으로 3rd party 도구가 레이크하우스에 저장된 데이터 쿼리가 가능합니다.
레이크하우스 아키텍처는 스토리지 레이어와 컴퓨팅 리소스가 분리되어있으므로, 워크로드에 알맞는 쿼리엔진을 골라서 사용할 수 있습니다.
예를 들어서 페타바이트 급의 대규모 데이터를 처리하는 용도로는 Presto, 데이터 분석용으로는 spark를 사용하는 경우를 생각해볼 수 있을 것 같습니다.
5. Data Consumption Layer
그래서 이런 아키텍처를 통해 데이터 소비자는 다양한 도구로 필요한 워크로드를 수행할 수 있게 됩니다.
댓글남기기