
etcdGRPCRequestSlow 원인파악 및 해결기
Environment
OS : RedHat CoreOS 4.12
Openshift : v4.12
Master Nodes(cpu/ram/storage): 16/64/500G X3
ERROR
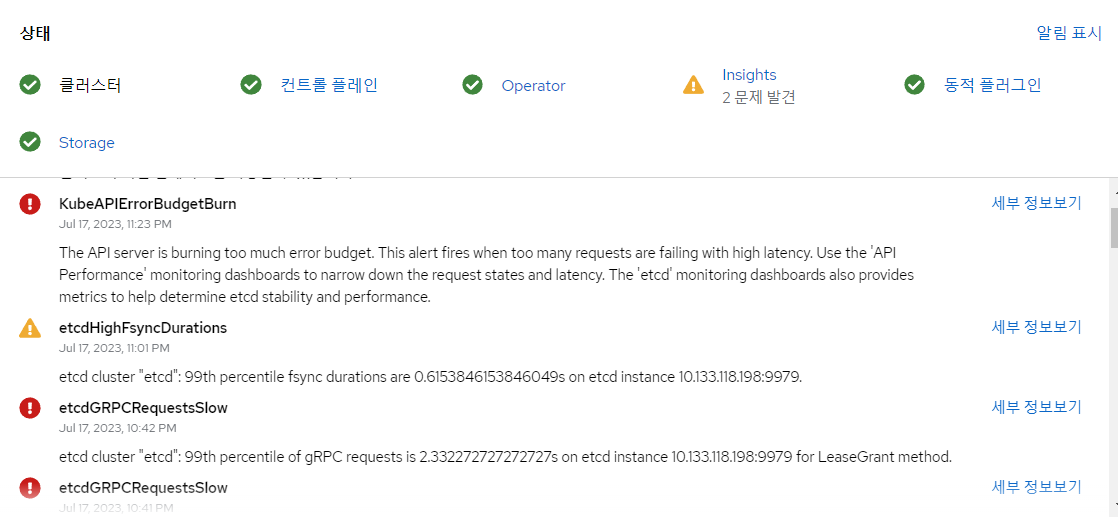
클러스터에서 지속적으로 etcdGRPCRequestSlow 에러 발생, API server에서의 ETCD connection timeout발생으로 인한 클러스터 불안정, OAuthServer의 Down을 야기
한마디로 클러스터를 정상적으로 운용하지 못하는 상황에 봉착했었습니다.
마스터노드에 할당해준 리소스는 워크로드에 충분한 양이었는데 왜?? 이런 일이 발생했던걸까요?
머리를 쥐싸매게 만든 “etcdGRPCRequestSlow“… 어떻게 해결했는지 기록을 남겨두려고 합니다.
Diagnosis
참고 링크 :
0. 범인은 누구
가장 먼저 CPU와 RAM이 부족하지 않았나 체크를 해봤습니다.
그런데 top이나 free등의 command로 체크를 해봐도 사용가능한 리소스가 넘치던 상황이었구요.
혹시 네트워크 문제인가 싶어서 latency 테스트도 해봤습니다.
$ curl -k https://{cluster_apiserver_url} -w "%{time_connect}\n"
....
0.001221
가이드에 따르면 2ms(0.002)이하로 나오면 정상, 6-8ms(0.006-0.008)이상이 나오면 문제가 있는것이라 하는데….
수치를 보면 network는 문제가 없어보입니다.
남은건 바로 디스크였습니다.
1. promQL로 주요 DISK metric 확인하기
etcdGRPCRequestSlow 이슈에서 가장 먼저 살펴봐야 할 metric은 etcd_disk_wal_fsync_duration입니다.
fsync는 데이터를 디스크에 기록하고, 성공적으로 기록되어야 반환되는 함수인데요, fsync가 실행되는데 걸리는 시간을 체크해둔 metric이 etcd_disk_wal_fsync_duration입니다.
histogram_quantile(0.99, irate(etcd_disk_wal_fsync_duration_seconds_bucket[5m]))
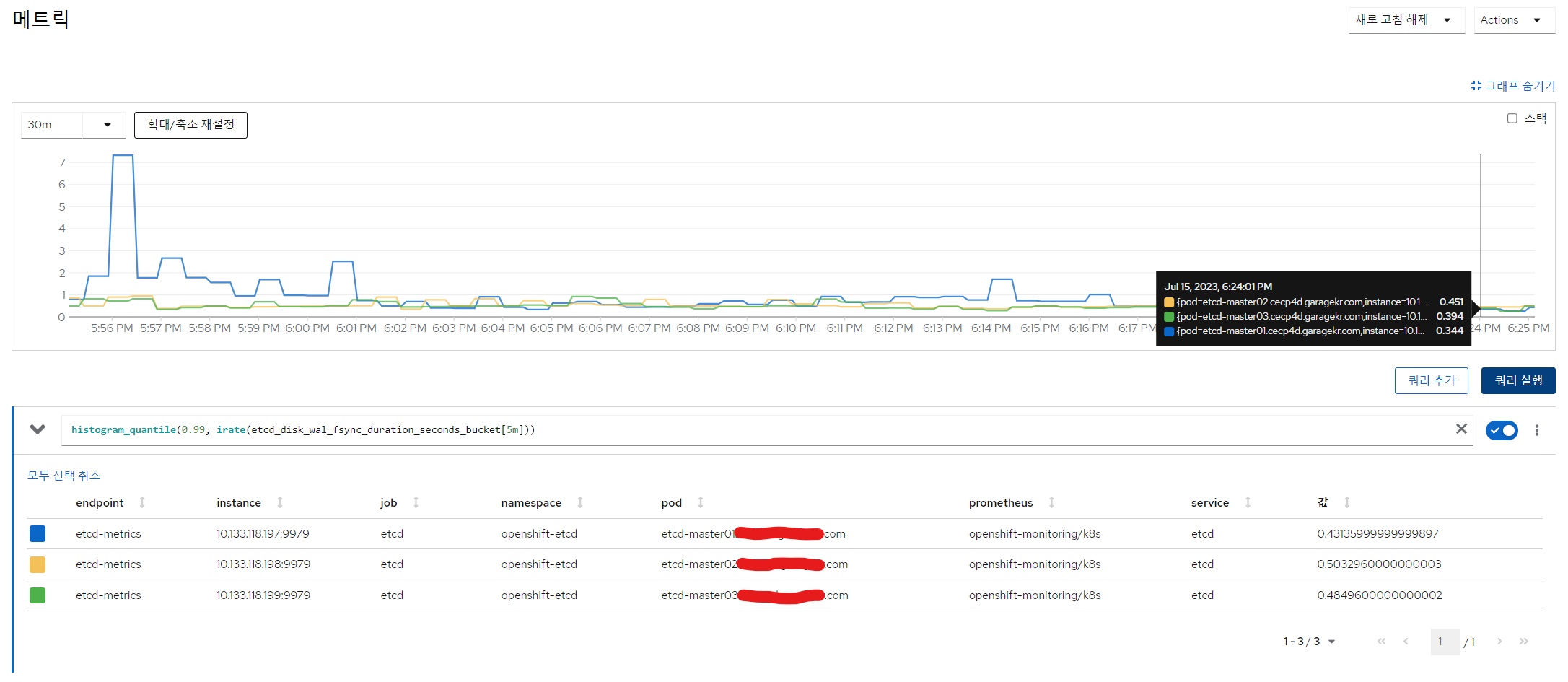
histogram_quantile(0.999, irate(etcd_disk_wal_fsync_duration_seconds_bucket[5m]))

두 지표 모두 권장사항은 0.015<x<0.02 사이여야하는데 아득히 상회하고 있는 모습을 확인할 수 있습니다.
2. ETCD performance Test
두가지 방법을 통해 test를 진행할 수 있습니다.
1.전반적인 DISK benchmark test
master노드 중 하나에 접속합니다.
$ oc debug node/<master_node>
[...]
sh-4.4# chroot /host bash
그 다음 openshift-etcd-suite이미지를 실행시켜 테스트를 진행합니다.
[root@master01 /]# podman run --privileged --volume /var/lib/etcd:/test quay.io/peterducai/openshift-etcd-suite:latest fio
아래는 실제 문제가 있었던 클러스터에서의 결과중 일부입니다.
...
FIO SUITE version 0.1.27
WARNING: this test can run for several minutes without any progress! Please wait until it finish!
[ RANDOM IOPS TEST ]
[ RANDOM IOPS TEST ] - REQUEST OVERHEAD AND SEEK TIMES] ---
This job is a latency-sensitive workload that stresses per-request overhead and seek times. Random reads.
1GB file transfer:
read: IOPS=234, BW=937KiB/s (960kB/s)(110MiB/120018msec)
--------------------------
RANDOM IOPS: IOPS=234
--------------------------
200MB file transfer:
read: IOPS=306, BW=1225KiB/s (1254kB/s)(144MiB/120140msec)
--------------------------
RANDOM IOPS: IOPS=306
--------------------------
[ SEQUENTIAL IOPS TEST ]
[ SEQUENTIAL IOPS TEST ] - [ ETCD-like FSYNC WRITE with fsync engine ]
the 99th percentile of this metric should be less than 10ms
cleanfsynctest: (g=0): rw=write, bs=(R) 2300B-2300B, (W) 2300B-2300B, (T) 2300B-2300B, ioengine=sync, iodepth=1
fio-3.30
Starting 1 process
cleanfsynctest: Laying out IO file (1 file / 22MiB)
cleanfsynctest: (groupid=0, jobs=1): err= 0: pid=108: Sat Jul 15 09:07:13 2023
write: IOPS=24, BW=55.8KiB/s (57.1kB/s)(22.0MiB/403805msec); 0 zone resets
clat (nsec): min=5298, max=94332, avg=15811.61, stdev=7763.87
lat (nsec): min=5564, max=95136, avg=16324.40, stdev=7938.34
clat percentiles (nsec):
| 1.00th=[ 7520], 5.00th=[ 8640], 10.00th=[ 9408], 20.00th=[10432],
| 30.00th=[11456], 40.00th=[12352], 50.00th=[13120], 60.00th=[14144],
| 70.00th=[15936], 80.00th=[20352], 90.00th=[28288], 95.00th=[31872],
| 99.00th=[41216], 99.50th=[47872], 99.90th=[64768], 99.95th=[70144],
| 99.99th=[90624]
bw ( KiB/s): min= 4, max= 166, per=98.59%, avg=55.91, stdev=29.15, samples=797
iops : min= 2, max= 74, avg=25.15, stdev=12.95, samples=797
lat (usec) : 10=16.51%, 20=63.05%, 50=20.05%, 100=0.39%
fsync/fdatasync/sync_file_range:
sync (msec): min=5, max=1523, avg=40.24, stdev=57.53
sync percentiles (msec):
| 1.00th=[ 6], 5.00th=[ 7], 10.00th=[ 9], 20.00th=[ 12],
| 30.00th=[ 16], 40.00th=[ 18], 50.00th=[ 23], 60.00th=[ 30],
| 70.00th=[ 39], 80.00th=[ 55], 90.00th=[ 87], 95.00th=[ 125],
| 99.00th=[ 268], 99.50th=[ 347], 99.90th=[ 642], 99.95th=[ 869],
| 99.99th=[ 1028]
cpu : usr=0.02%, sys=0.11%, ctx=31762, majf=0, minf=15
IO depths : 1=200.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,10029,0,0 short=10029,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=55.8KiB/s (57.1kB/s), 55.8KiB/s-55.8KiB/s (57.1kB/s-57.1kB/s), io=22.0MiB (23.1MB), run=403805-403805msec
Disk stats (read/write):
sda: ios=0/41966, merge=0/1061, ticks=0/1289800, in_queue=1289800, util=86.84%
--------------------------
SEQUENTIAL IOPS: IOPS=24
OK.. 99th fsync is less than 10ms (10k). 268
--------------------------
[ SEQUENTIAL IOPS TEST ] - [ libaio engine SINGLE JOB, 70% read, 30% write]
--------------------------
1GB file transfer:
read: IOPS=94, BW=380KiB/s (389kB/s)(44.5MiB/120019msec)
write: IOPS=40, BW=161KiB/s (165kB/s)(18.9MiB/120019msec); 0 zone resets
SEQUENTIAL WRITE IOPS: 40
SEQUENTIAL READ IOPS: 94
--------------------------
--------------------------
200MB file transfer:
read: IOPS=80, BW=321KiB/s (329kB/s)(37.6MiB/120001msec)
write: IOPS=34, BW=138KiB/s (142kB/s)(16.2MiB/120001msec); 0 zone resets
SEQUENTIAL WRITE IOPS: 34
SEQUENTIAL READ IOPS: 80
--------------------------
-- [ libaio engine SINGLE JOB, 30% read, 70% write] --
--------------------------
200MB file transfer:
read: IOPS=22, BW=91.1KiB/s (93.3kB/s)(10.7MiB/120002msec)
write: IOPS=53, BW=214KiB/s (220kB/s)(25.1MiB/120002msec); 0 zone resets
SEQUENTIAL WRITE IOPS: 53
SEQUENTIAL READ IOPS: 22
--------------------------
--------------------------
1GB file transfer:
read: IOPS=20, BW=82.6KiB/s (84.5kB/s)(9908KiB/120008msec)
write: IOPS=49, BW=197KiB/s (202kB/s)(23.1MiB/120008msec); 0 zone resets
SEQUENTIAL WRITE IOPS: 49
SEQUENTIAL READ IOPS: 20
--------------------------
- END -----------------------------------------
required fsync sequential IOPS:
50 - minimum, local development
300 - small to medium cluster with average load
500 - medium or large cluster with heavy load
800+ - large cluster with heavy load
가이드에 따르면 일반적으로 sequential IOPS는 1500-2000정도는 나와야 괜찮은 성능을 낼 수 있다고 합니다.
2.ETCD benchmark
다음은 ETCD 클러스터를 대상으로 한 benchmark테스트입니다.
위와 동일하게 마스터노드 중 하나에 접속해서 아래 이미지를 실행시킵니다.
[root@master01 /]# podman run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/openshift-scale/etcd-perf
결과:
...
---------------------------------------------------------------- Running fio --------------------------------------------------------------
-------------
{
"fio version" : "fio-3.27",
"timestamp" : 1689419552,
"timestamp_ms" : 1689419552474,
"time" : "Sat Jul 15 11:12:32 2023",
"global options" : {
"rw" : "write",
"ioengine" : "sync",
"fdatasync" : "1",
"directory" : "/var/lib/etcd",
"size" : "100m",
"bs" : "8000"
},
...
"disk_util" : [
{
"name" : "sda",
"read_ios" : 0,
"write_ios" : 9470,
"read_merges" : 0,
"write_merges" : 6076,
"read_ticks" : 0,
"write_ticks" : 1646179,
"in_queue" : 1646178,
"util" : 89.692664
}
]
}
-------------------------------------------------------------------------------------------------------------------------------------------
-------------
INFO: 99th percentile of fsync is 692060160 ns
WARN: 99th percentile of the fsync is greater than the recommended value which is 692060160 ns > 20 ms, faster disks are recommended to host etcd for better performance
마지막 경고 문구를 보면 권장 fysnc 속도는 20ms미만이라고 나와있습니다.
etcd-perf실행결과가 ns로 나와서 헷갈리지만 ms로 환산하면 대략 692.06016ms입니다.
3. 결론
위의 성능 테스트를 통해 얻은 결론 : DISK가 어마어마하게 느리다!!!
etcd는 클러스터의 메타정보들을 저장하는 key-value store로, 클러스터의 상태값이 바뀔때마다 그 정보들을 디스크에 쓰고 읽으니,
클러스터 워크로드가 늘어감에 따라 정보량이 많아지고 느린 디스크로는 감당할 수 없게 된것이 아닌가 싶습니다.
이 당시 스토리지를 SSD가 아니라 HDD를 쓰고있었는데 솔직히 이정도로 느릴 줄은 몰랐습니다. 거의 테이프수준
Solution
마스터 노드의 HDD를 전부 SSD로 바꿔주기
여담으로 마스터노드만 SSD로 바꾸고 나머지 워커노드는 HDD로 계속 갔다가 DB pod띄우고 혈압터져서 결국 모든 노드의 스토리지를 SSD로 바꿨습니다.
가능하면 DB나 MQ같은 file read/write 성능이 중요한 workload를 돌릴 예정이라면 모든 노드를 SSD로 가져가는 것이 좋을 것 같습니다.
댓글남기기