
호다닥 톺아보는 합의 알고리즘 : PAXOS, RAFT
Distributed System과 Consensus Algorithm
싱글 컴퓨터로는 성능의 향상에 있어 제한이 있습니다. 만약 해당 컴퓨터에 장애가 발생한다고 한다면 꼼짝없이 돌아가던 서비스도 멈추게 될거고요.
그래서 복잡한 연산을 여러 컴퓨터가 나눠서 수행하고, 하나의 컴퓨터가 망가지더라도 나머지 컴퓨터가 맡아서 처리할 수 있는 분산 환경(Distributed System)이 등장하게 됩니다.
하지만 결국 여러 컴퓨터가 하나의 시스템처럼 동작하려면, 누구하나 어긋남 없이 하나의 상태를 가져야 합니다.
이런 문제를 해결하기 위해 분산 환경에서 상태를 공유하는 알고리즘이 등장했고, 이를 Consensus Algorithm이라고 부릅니다.
Fail-Stop과 Byzantine Failure
분산 환경에서 발생할 수 있는 장애는 무궁무진하지만 이 문서에서는 합의와 관련된 부분만 다루도록 하겠습니다.
크게 두가지 종류가 있습니다.
Fail-Stop: 단순히 노드가 고장나서 멈추는 형태Byzantine Failure: 고장나서 멈추는 것을 넘어서서 노드가 악의적인 행동을 포함한 임의의 동작을 할 수 있다는 문제
Fail-Stop형태의 장애를 가정한 대표적인 합의 알고리즘으로는 Paxos와 Raft가 있고,
Byzantine Failure를 가정한 대표적인 합의 알고리즘으로는 PBFT가 있습니다.
이 문서에서는 Paxos와 Raft에 대해서 알아보도록 하겠습니다.
Paxos
Paxos 알고리즘은 1989년에 처음 공개되었으며 그리스의 팩소스 섬에서 가상의 입법 합의 시스템에 사용된 후 이름지어졌습니다.
분산 시스템에서 여러 프로세스 간에 하나의 값에 동의하기 위한 프로토콜로서, 동시에 여러 개의 값이 제안되지만,
결국에는 이 중 하나의 값이 선택되도록 하는 것이 골자입니다.
하지만 여러 제안자에 의해 동시에 여러 값의 후보가 제안될 수 있다는 점 때문에 프로토콜의 동작이 복잡해 구현이 어렵다는 단점이 있습니다.
사실 글을 쓰는 저도 100% 이해했다고 말하긴 어렵지만, 아래 영상을 보고 제가 이해한 내용을 최대한 쉽게 풀어써보고자 합니다.
Overview

- Paxos알고리즘은 총 세개의 역할을 정의합니다.
Proposer: 특정 값을 제안함Accepter:Proposer에게 온 값들중에 하나를 선택함Learner:Accepter에 의해 합의된 값을 전달받음
- 각 paxos 노드는 과반수의
Accepter개수를 알고있음 (Accepter가 3이면 과반은 2, 과반이 동의하면 나머지 하나의 의견은 묵살) Accepter들은 한번 특정 값을 받아들이게 되면 (다수의Accepter가 동의해서 commit이 되면) 그 값은 변하지 않는다 (Proposer가 새로운 값을 제안해도 무시함)- Paxos알고리즘의 목표는 단 하나의 consensus를 이루는 것!
Basic Paxos
그럼 실제로 Paxos알고리즘을 통해 어떤식으로 합의가 이루어지는지 보도록 하겠습니다.
Proposer가 1개일 경우
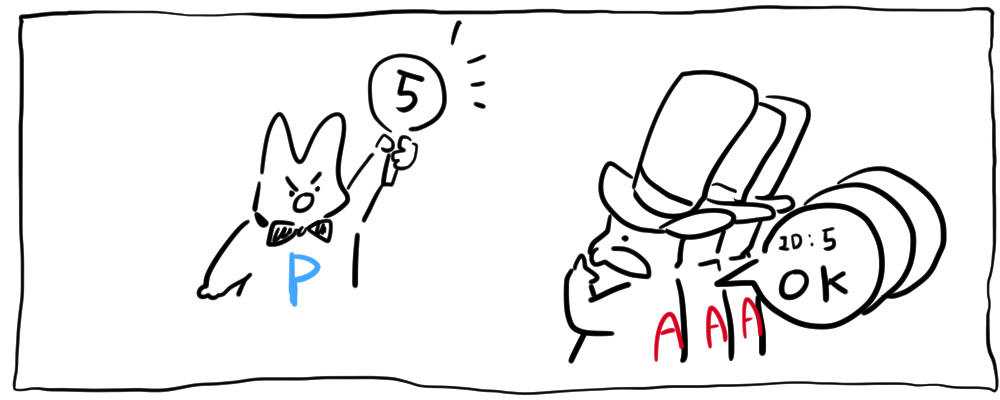
- PREPARE :
Proposer가 어떤 값을 제안하기 위해 제안번호(ID)를 먼저Accepter들한테 보냄 - PROMISE :
Accepter는 제안한 번호(ID)이하의 값을 받지 않겠다고 약속 (ex. 5가오면 5이하의 숫자는 무시됨)
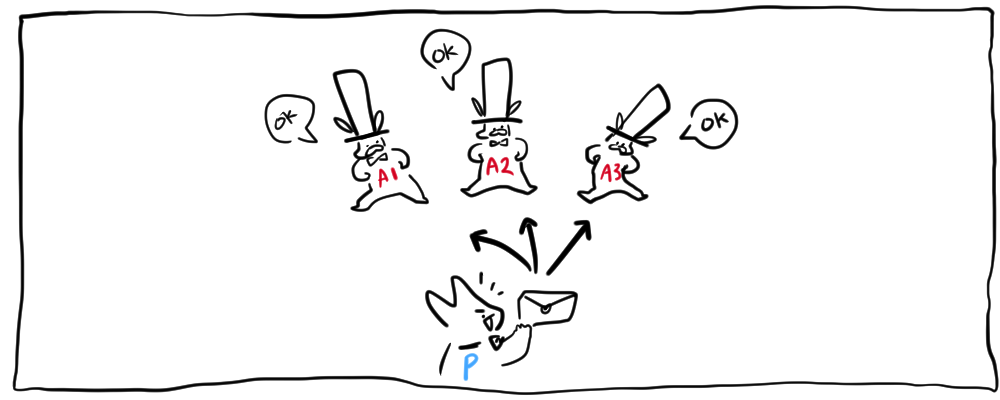
- ACCEPT : 다수의
Accepter가 동일한 ID의 PROMISE메세지를Proposer에게 보냈다면Proposer는 해당 ID와 VALUE를Accepter에게 보냄

- ACCEPTED :
Accepter는 메세지(ID,VALUE)를 받고 ID가 마지막으로 약속한 값인 경우에만 VALUE를 받아들이고 VALUE를Proposer와Learner에게 전파한다 만약 마지막으로 약속한 값이 아닐경우Accepter는 메세지를 무시할 수 있고, 거절응답을 P에게 보낼 수 있음 - 합의완료
Proposer가 여러개일 경우
만약 다른 Proposer가 network latency등의 이유로 합의된 값을 받지 못하고 새로 제안했을 경우
Proposer2는 제안번호4를Accepter에게 보냄- 하지만 이미
Accepter는 제안번호5를 승인한 전적이 있음 -> 4<5이므로 reject Proposer2는 더 높은 제안번호 6을 보냄Accepter는 5보다 더 높은 제안번호인 6을 승인함- 이미 이전에 5,cat이라는 제안을 합의했기때문에
Accepter는 새로받은 제안번호에 합의했던 value인 cat을 붙여서 약속 메세지를 보냄 Proposer2는 받은 value와 승인된 제안번호와 함께 ACCEPT REQUEST를 보냄Accepter는 요청을 보고 이미 위에서 합의된 value가 아니라면 무시/거절, 합의된게 맞다면 value 전파
그래서 한장으로 정리하면 아래와 같은 도식이 그려지게 됩니다.

Image from “Google TechTalks: The Paxos Algorithm”
이 외에도 여러 if시나리오가 있지만, 이 문서에서는 그렇게 deep하게 다루지는 않을 생각입니다.
관심이 있으신 분들은 아래 링크를 참조해주시기 바랍니다!
참고링크
Raft
위의 Paxos알고리즘을 보시면 아시겠지만 한 번 합의를 이루는 절차가 꽤나 복잡합니다.
절차가 복잡하니 이해가 어렵고 구현이 어려워, 실제로 Paxos를 구현한 라이브러리가 거의 없었고 일부 분산 시스템이 내부적으로 사용하는 정도 였다고 합니다.
하지만 분산 시스템이 주류가 되고 있는 요즈음, 더욱 알기 쉽고 구현하기 쉬운 합의 알고리즘에 대한 요구사항은 높아져왔고
2014년 USENIX에서 “In Search of an Understandable Consensus Algorithm”라는 논문이 발표되고 Raft라는 알고리즘이 등장하게 됩니다.
Raft는 논문 제목에서 알 수 있듯이 “이해 가능한” 합의 알고리즘을 만드는 데 초점을 두고 있습니다.
논문의 저자들은 Paxos와 Raft중 어떤게 더 이해하기 쉽고 구현하기 쉽겠느냐고 스탠포드대학 컴퓨터공학과 학생들에게 survey를 진행했고, 결과는 다음과 같았다고 한다..!!!
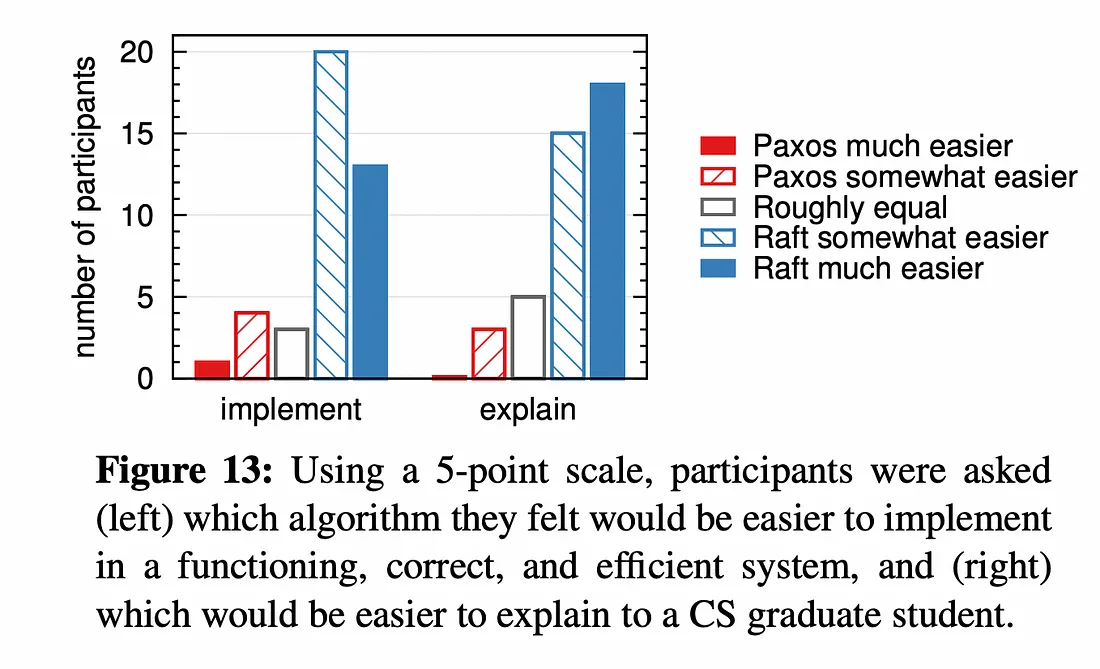
그럼 지금부터 Paxos와 동일한 결과와 효율성을 지니고 있지만 구조(방법)는 Paxos와 다른! Raft 알고리즘에 대해 알아보도록 하겠습니다.
상태
Raft알고리즘 상에서 분산 시스템의 모든 노드들은 세가지 상태 중 하나를 가지게 됩니다.
Leader: 리더는 클라이언트의 모든 요청을 수신받고, 로컬에 로그를 적재하고 모든follwer에게 전달Follwer: 클라이언트로 받은 요청을 리더로 redirect 시켜주고, 리더의 요청을 수신하여 처리하는 역할Candidate: 새로운 리더를 선출하기 위해 후보가 된 상태
Paxos에서 각 노드가 역할이 정해져있었던 것과 다르게 Raft에서는 상태만 변할 뿐이지 고정된 역할이 없습니다.
1. 리더 선출(Leader Election)
분산 시스템에서 각 노드들은 내부적으로 임기를 가지고 있습니다.
대통령 선거하듯이 1대, 2대 이런식으로요.
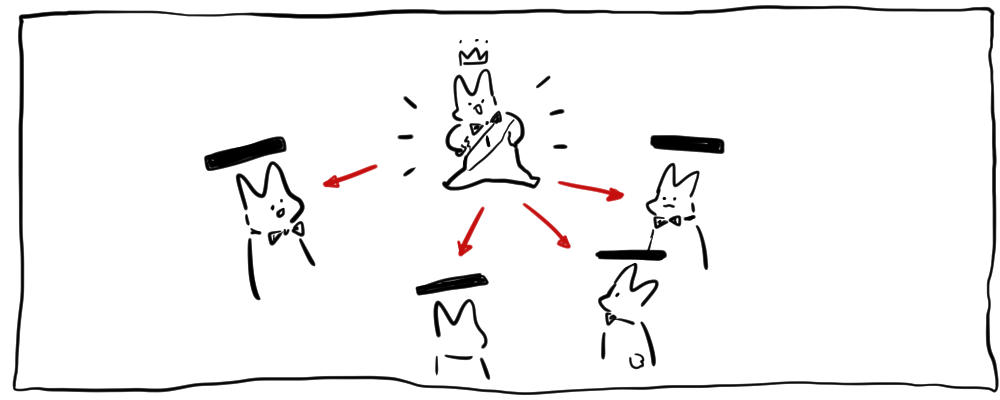
리더로 선출된 노드는 주기적으로 비어있는 AppendEntries라는 RPC프로토콜을 사용해 follower들에게 자신이 살아있다는 것을 알립니다.
(새로운 엔트리를 follower에게 전파할때도 동일한 프로토콜 사용)
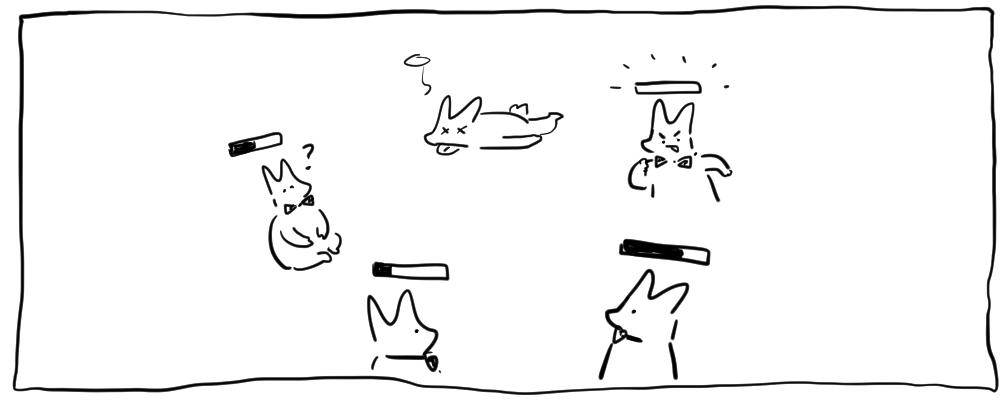
각 노드는 150ms~300ms 사이의 랜덤하게 할당된 타임아웃 시간이 존재하고,
follower는 특정 시간동안 리더한테서의 신호를 받지 못하면 자신이 리더가 되기위해 반란을 일으킵니다.
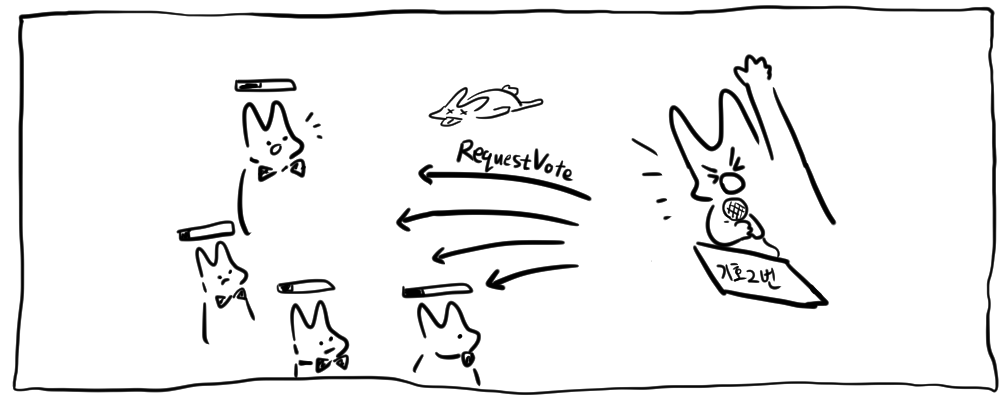
- 저장된 임기번호(term)을 1증가시키고 새로운 선거를 진행
- 본인이 스스로 후보(candidate)가 되어 자신에게 투표를 진행하고 다른 follower들에게 투표요청
RequestVoteRPC 프로토콜을 사용해 함수를 호출한다
그렇게 투표가 시작되면 아래 세가지 결과중 하나를 얻게 됩니다.
- 과반수의 투표를 얻어 리더로 당선
- 동일한 시점에 후보가 된 다른 노드가 리더가 됨 -> 리더가 되지못한 candidate는 follower로 상태를 변경하고 새로운리더를 등록함
- 승자 없이 투표종료(동률이거나 모든 노드가 자신에게 투표했을 경우 발생) -> 이경우 임기를 1증가시키고 다시 투표요청
2. 로그 복제(Log Replication)
리더가 정해지고 나서는 시스템의 모든 변경사항이 리더를 통하게 됩니다.
각 변경사항은 로그엔트리(log Entries)에 저장되고 다른 follower들에게 복제됩니다.
로그 엔트리
- Term : 임기
- Index : log 저장할때의 번호 (1부터시작함)
- Data

1.클라이언트가 리더에게 변경사항을 보냄
2.변경사항은 리더의 로그엔트리에 저장됨

3.AppendEntries RPC를 호출해서 log를 전달
4.Follower는 새로받은 로그를 저장하고 성공 응답을 보냄
AppendEntries RPC Arguments:
term: 현재 leader의 임기 leaderId : leader id prevLogIndex : 바로 이전의 log index prevLogTerm : 바로 이전의 log index에 기록된 임기(term) entries[] : 저장할 로그 엔트리 (비어있으면 heartbeat용) leaderCommit : 현재 leader의 commitIndex
AppendEntries상세 동작 순서:
- Follower가 갖고 있는 현재임기(
currentTerm)보다 전달받은term이 낮으면(term<currentTerm) -> return false- 전달받은
prevLogIndex에 해당하는 엔트리가 없다면 -> return false (ex. leader의 index는 3인데 복사하려는 follower의 index가 1이어서prevLogIndex인 2에 해당하는 entry가 없는 경우)- 이미 존재하는 엔트리가 새로운 엔트리와 충돌이 발생할 경우(같은index지만 다른term일 경우) -> 기존 엔트리 삭제
- 새로운 엔트리를 추가
- “새로 추가된 엔트리의 index”와 “leader의 commitIndex”중 작은 값을 follower의 commitIndex에 set

5.과반수 follower의 응답을 받았으면 리더는 자신의 로그엔트리를 커밋하고 클라이언트에 응답을 보냄
6.follower들한테도 변경사항이 커밋되었음을 알림 -> follower들 자신의 로그엔트리 커밋
Leader Completeness
아래 사진의 경우에서는
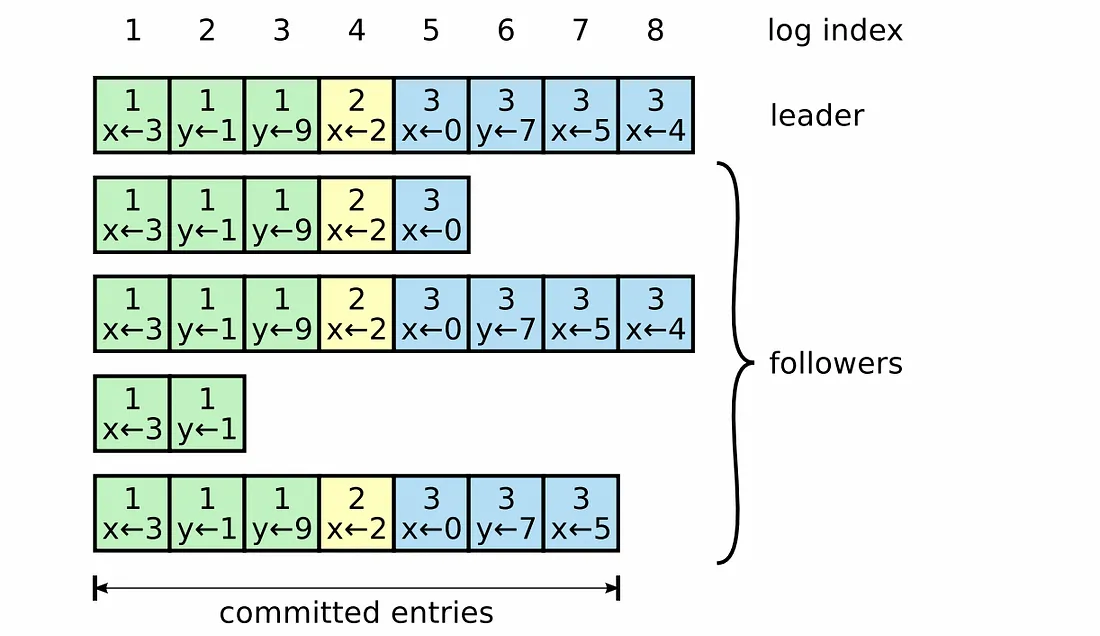
과반수의 노드(여기선 3개의 노드)에 복제되었으므로 커밋된 것으로 간주하고, 이를 Committed Entries(여기서는 7)라고 칭합니다.
한 번 커밋된 엔트리는 다음 임기의 리더들에게 반드시 포함될 것을 보장하는데, 이를 Leader Completeness라고 합니다.
이게 어떻게 보장될 수 있을까요?
다시한번 AppendEntries의 동작을 되짚어보겠습니다.
리더는 새로운 엔트리를 다른 서버로 전파할 때 AppendEntries RPC를 호출합니다.
문제 없이 성공한다면 로그엔트리를 복사하고, 실패한다면 인덱스 값을 1씩 감소시켜서 성공할 때까지 반복하고 성공한다면 로그를 복사합니다.
그것을 과반수의 follower들에게 전파를 성공한다면 위에 언급한 것처럼 commit을 하게 됩니다.
여기서 살펴봐야 할 것은 두가지 입니다.
- Election Restriction (선거 제약)
- Candidate는 Leader가 되려면 과반수 노드의 투표가 있어야 함
RequestVoteRPC에는 Candidate의 마지막 로그의 index와 term이 파라미터로 포함되어있는데, 요청을 받은 투표자(Follower)의 index나 term이 더 높으면 요청을 거절함
- Commit Rules (커밋 규칙)
- Raft에서는 반드시 현재 임기의 로그가 복제되어야만 커밋으로 간주한다.
Raft에서는 위 두가지 규칙을 통해서 Leader Completeness를 보장하고 있습니다.
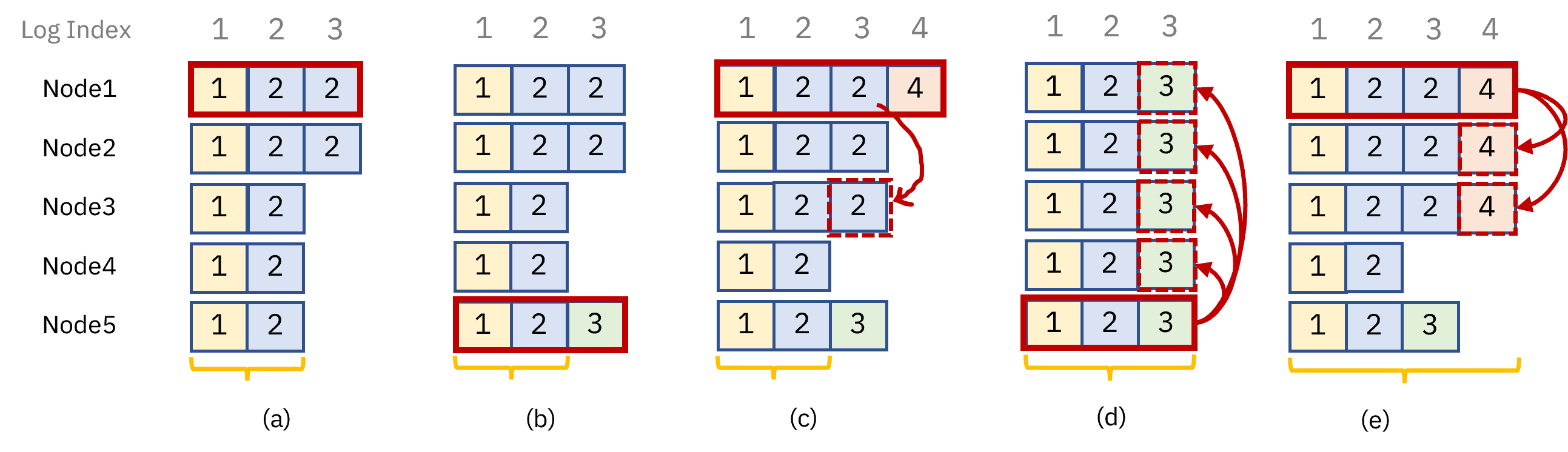
박스안의 숫자는 임기를 의미합니다.
한 번 순서를 따라가보도록 하겠습니다.
(a) : 2대리더는 1번노드입니다. 2번 index까지 과반수의 노드에 전파가 되어서 커밋이 되었습니다. (commitIndex=2)
(b) : 3번 index가 다수의 노드에 전파되어 커밋되기전에 -> 5번노드가 각 노드에게 투표를 요청합니다. -> 1번과 2번노드에게는 선거제약 규칙때문에 투표를 거절당하고, 3번,4번노드에게 표를 받아서 5번노드가 3대리더가 되었습니다. (commitIndex=2)
(c) : 다시 1번노드가 2~4번 노드에게 표를 받아 4대리더가 됩니다. -> 그리고 3번 index를 노드3번에 복사하여 과반수 노드에 전파를 성공했습니다. -> 하지만 이는 커밋규칙에 따라 현재임기의 로그가 아니므로 커밋되었다고 할 수 없습니다.
(d) : 만약 5번노드가 2~4번 노드에게 표를 받아 다시 리더가 된다면 이전 것을 덮어씌우기 때문입니다. (commitIndex=3)
(e) : 하지만 (c)상황에서 1번노드가 4번 index까지 무사히 과반수 노드에 전파를 성공해 커밋한다면 5번노드는 당선될 수 없습니다.(commitIndex=4)
일련의 과정을 통해 리더가 바뀌더라도 이전에 커밋했던 index들은 계속 유지된다는 것을 확인할 수 있습니다.
- 커밋은 과반수 노드에 전파되어야 함
- 리더는 과반수 노드의 투표가 있어야 당선됨
더 자세한 증명과정은 논문을 참고 -> In Search of an Understandable Consensus Algorithm: 5.4.3 Safty argument
주저리
글을 쓰다보니, paxos알고리즘이 이해하기 어렵다고 하는데 저는 개인적으로 raft가 더 어려웠던 것 같습니다.
paxos는 그냥 핥아보기만하고 raft는 깊게 파고들어서 그런걸까요?ㅋㅋㅋ
아니면 이정도는 누워서 떡먹기라고 생각하는 스탠포드 학생들이 대단한 것일까요….
역시 컴퓨터 굇수들은 무서워요

댓글남기기