
KVM에서 GPU passthrough하기
OverviewPermalink
엔터프라이즈급 가상화 플랫폼이라고 하면 생각나는 몇몇 솔루션들이 있습니다.
하지만 라이센스 문제라던가 가격 등의 문제로 상용솔루션을 쓰지못하는 경우도 있죠.
그럴때 생각해 볼 수 있는 방법은 무엇이 있을까요..?
여러가지 생각해볼 수 있겠지만
오늘은 근본중의 근본, 리눅스 커널 기반으로 만들어진 오픈소스 가상화 기술 KVM(Kernel-based Virtual Machine)을 다뤄볼 겁니다.
아마 컴퓨터세상에 발을 좀 담궈봤던 사람이라면 익숙한 이름일겁니다.
리눅스 서버 위에서 가상머신을 만들기 위해서는 모를수가 없는 기술이죠.
최근 AI관련 워크로드가 늘어나면서 GPU에 대한 수요도 높아지고 NVLink나 NVSwitch를 탑재한 고성능 GPU서버들도 늘어나고 있습니다.
우리가 VM을 사용하려는데에는 여러가지 이유가 있겠지만, 그 중 하나는 리소스를 최대한 효율적으로 사용하기 위해서이죠.
그러려면 CPU나 RAM뿐만아니라 여러 PCI장치들(ex. GPU)을 VM위에서 사용할 수 있어야 될겁니다.
저도 지금까지 여러 프로젝트를 뛰어오면서 다양한 환경을 만났는데요.
대부분의 엔터프라이즈 기업들은 ESXi기반의 가상화 솔루션을 사용하고 있어서 사실 편하게(?) PCI장치들을 VM에서 사용할 수 있었습니다.
하지만 KVM은… 뭐 여러 GUI기반의 솔루션들이 도와준다고는 하지만.. 커널 파라미터를 수정해야하기도 하고 GUI가 안된다면 검정배경에 흰글씨만보고 VM만 만들어야하는….. 근본오브근본이지만 난이도는 결코 쉽지 않은.. 그런 느낌입니다.
말이 너무 길었네요. 이거때문에 삽질을 너무 많이해서 말이 길어졌나봅니다.
각설하고 오늘의 포스팅은 바로 KVM에서 GPU passthrough를 하는 방법에 대해서 알아보도록 하겠습니다!
개념 정리Permalink
DMA(Direct Memory Access)Permalink
CPU가 I/O장치들과 데이터를 주고받는 방법을 PIO(Programmed Input/Output)라고 합니다.
메모리를 통해서 외부 장치와 데이터 통신을 하던지, 별도의 I/O영역을 통해서 통신을 하던지, 결국 CPU가 직접 명령어를 수행하게 됩니다.

그러나 이러한 방식은 모두 CPU에 부하를 주는 방식들입니다.
또한 I/O장치들은 CPU보다 상대적으로 “느리죠”. 그렇기 때문에 외부장치의 응답을 기다리다가 정말 중요한 작업의 대기시간이 길어질 수도 있겠죠!
I/O장치를 사용하는 일이 많아질 수록 CPU에 인터럽트를 거는 주기도 늘어나서 CPU 사이클을 비효율적으로 만들게 될 수도 있습니다.
그래서 이러한 I/O장치들이 CPU와 독립적으로 시스템 메모리에 접근할 수 있게 해주는 DMA(Direct Memory Access) 라는 기술이 등장하게 됩니다.
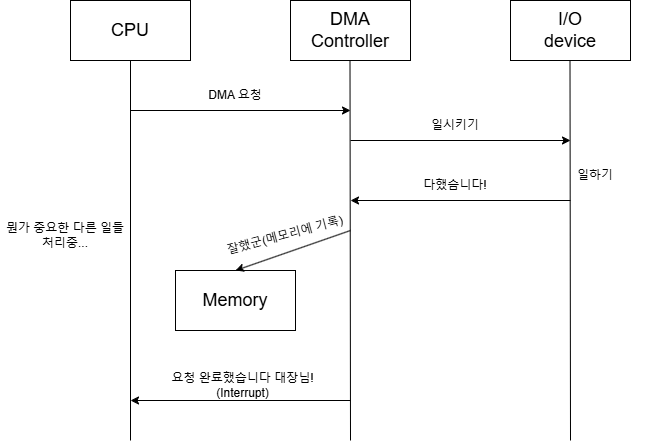
DMA는 메모리 영역에 직접 액세스할 수 있기 때문에 CPU가 DMA에게 요청을 하면 DMA가 외부 디바이스와 통신을 주고받고, 그 결과를 특정 메모리 영역에 씁니다.
작업이 다 끝나고나면 CPU인터럽트를 발생시켜서 그 결과물을 읽어가도록 하게 하죠.
디스크 드라이브, GPU, 네트워크 카드, 사운드 카드 등등이 DMA를 사용하고, 메모리간 복사 또는 데이터 이동에도 DMA가 사용될 수 있습니다.
MMU(Memory Management Unit) & IOMMU(Input Output Memory Management Unit)Permalink
그러나 DMA는 보안적으로 큰 위험요소가 될 수도 있는데요,
메모리 영역에 직접적으로 액세스할 수 있는만큼, PCIe장치가 잘못된 메모리 주소를 접근하게 되면 시스템이 불안정해지거나 보안 취약점이 생길 수도 있습니다.
그래서 일반적으로 OS는 메모리영역을 가상 주소(Virtual Address)로 관리합니다.
이를 통해 잘못된 메모리 접근을 차단하고, OS커널 영역같은 중요한 영역을 보호할 수 있게 되죠.
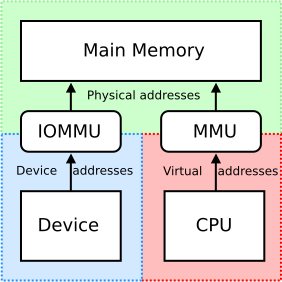
각 프로세스는 독립적인 가상의 주소 공간을 가지며, 실제로는 서로 다른 메모리 영역에 매핑되어 한 프로세스의 메모리가 다른 프로세스에 영향을 주지 않게 됩니다.
이 때 프로세스의 가상 주소를 물리 주소로 매핑하는 역할을 MMU(Memory Management Unit) 가 하게 됩니다.
그럼 PCIe장치는 시스템 메모리에 어떻게 접근을 하게 될까요?
PCIe의 경우도 동일합니다.
각자 가상의 주소공간을 갖고 있고 그것을 실제 물리 주소로 변환해주는 역할을 하는 녀석을 IOMMU(Input Output Memory Management Unit) 라고 합니다.

PCIe장치가 DMA요청을 보냄(가상주소) -> IOMMU가 가상주소를 물리주소로 변환 -> 변환된 요청이 올바르면 DMA요청을 허용, 잘못된 주소면 차단
그리고 이 IOMMU가 관리하는 PCI 장치들의 논리적인 묶음을 IOMMU Group이라고 합니다.
PCI PassthroughPermalink
이러한 기능은 VM에서 PCIe장치를 사용하기위해 필수가 되었는데요.
VM도 호스트OS처럼 자신의 메모리 관리를 해야하고 이는 실제 호스트의 물리 주소가 아닌 가상의 주소 테이블일겁니다.
그래서 VM 내부에서 프로세스가 보는 가상의가상주소 -> VM이 생각하는 물리주소(사실은 가상인) -> 실제 호스트 메모리상의 주소로 이루어진 복잡한 메모리 변환 방식을 거치게 됩니다!
PCIe장치는 VM의 가상주소를 (당연히)모르고, VM환경에서는 진짜 물리 주소를 쓰면 안되죠!
그래서 그 사이, 가상주소를 물리주소로 바꿔주는 IOMMU가 필수로 필요하게되고,
이를 통해 VM이 PCIe에게 가상주소로 DMA를 요청하더라도 IOMMU가 주소를 변환하여 정상작동을 하게 됩니다.
이렇게 VM이 하이퍼바이저의 도움 없이 직접 PCIe에 접근하는 개념을 PCI Passthrough라고 합니다.
Kernel Space & User SpacePermalink
그러면 어떻게 PCI Passthrough를 할 수 있는지 이야기를 하기 전에, 먼저 리눅스 운영체제의 메모리 공간에 대해서 보겠습니다.
리눅스에서는 메모리 공간을 User Space와 Kernel Space로 엄격하게 구분하여 한 쪽에서 생기는 문제가 다른 공간에 영향을 주지 않도록 설계되어 있습니다.
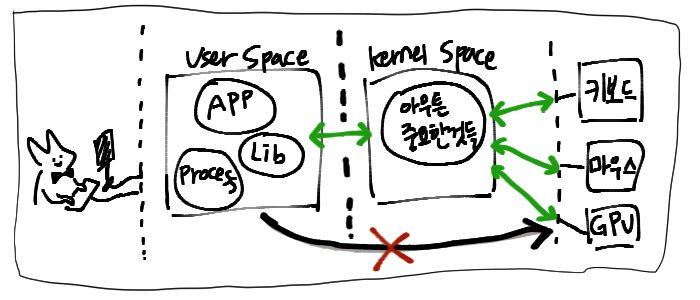
User Space
- Process, Application, Library등 사용자 레벨의 프로그램이 실행되는 영역
- 이 공간의 프로그램들은 직접 하드웨어나 시스템 자원에 접근하는것이 제한됨
- 파일 작성, 네트워크 접근, 메모리 할당 등의 시스템 영역의 작업을 수행하려면 커널에 서비스를 요청해야 함
Kernel Space
- OS의 핵심인, 커널이 실행되는 메모리 영역, 시스템의 모든 핵심 기능과 하드웨어 제어를 담당
- 하드웨어 자원을 직접 제어하며 드라이버를 통해 다양한 장치와 상호작용
- 메모리/프로세스/보안/인터럽트 등의 주요 시스템 작업 처리
이 두 공간은 서로 분리되어 있기 때문에 사용자 프로그램이 커널 메모리를 직접 건드릴 수 없게 보호할 수가 있습니다.
그러면! 오늘의 주제인 PCI장치로 다시 넘어와봅시다.
PCI장치는 하드웨어입니다. 위에서 언급했듯이 User Space에서 동작하는 사용자 프로그램들은 하드웨어에 직접 접근할 수가 없습니다.
그럼 우리는 어떻게 PCI 장치를 사용할 수 있는걸까요?
여기서 등장하는게 바로 Driver입니다!
(잘 생각해보면 새로 마우스를 사던 스피커를 사던, 제조사의 드라이버가 자동으로든 수동으로든 컴퓨터에 깔려야 장치를 인식하고 사용할 수 있게 되죠.)
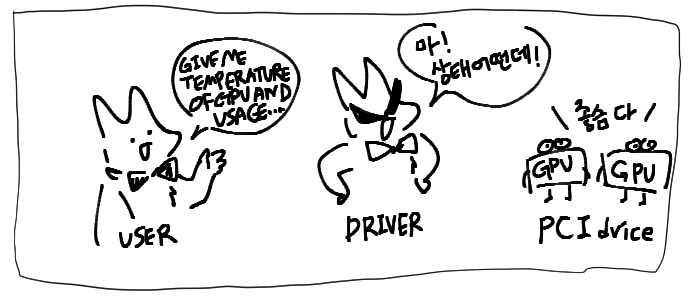
Driver는 Kernel Space에서 동작하는 프로그램으로, PCI컨트롤러를 통해 장치와 직접 통신할 수 있습니다.
즉, CPU와 PCIe장치간의 직접적인 인터페이스 역할을 하는 것이죠!
그리고 User Space에서 동작하는 프로그램은 System Call을 통해 커널 영역에 있는 드라이버에 요청을 보내 장치를 사용할 수 있게 됩니다.
사용자 프로그램 -> Driver -> PCI장치 순으로 Driver가 중간다리 역할을 하게 됩니다.
정리하면 User Space에서 실행되는 프로그램은 직접 하드웨어를 건드릴 수 없고, 반드시 Driver를 통해서만 접근하게 된다는 것입니다.
VFIO(Virtual Function I/O)Permalink
참고 : https://docs.kernel.org/driver-api/vfio.html
이제 우리는 PCI장치를 사용할 때 시스템 메모리 영역에 직접 액세스 하는 것이 아니라 가상주소를 사용한다는 것,
그리고 가상주소를 물리주소로 매핑하기 위한 IOMMU와,
유저의 프로그램에서 PCI장치를 사용하려면 반드시 Driver가 필요하다는 것을 알았습니다!
그렇다면 이제 VM을 만들고 GPU만 등록해서 nvidia driver를 설치하면 사용이 가능한걸까요?
슬프지만 안됩니다… 아직 한 단계가 더 남았어요….
일반적으로 PCI장치는 동시에 여러 OS에서 사용될 수 없습니다.
PCI장치를 사용하려면 I/O와 인터럽트 관리를 OS가 직접 해야하는데,
호스트 OS가 장치를 점유해서 사용하고 있는 와중에 게스트OS가 같은 장치를 제어하려고 하면 충돌이 발생하게 되겠죠.
그래서 VM에서 PCI장치를 사용하려면, 호스트OS가 해당 장치를 포기하게 만들어야 합니다.
VFIO(Virtual Function I/O) 는 User Space의 프로그램들이 PCI장치를 액세스할 수 있게 하기 위한 프레임워크입니다.
VFIO-PCI드라이버를 통해서 호스트 OS가 (GPU의 경우) nvidia나 nouveou같은 드라이버를 로드해 장치를 점유하지 않게 하고,
VM에서 장치를 사용할 수 있도록 넘겨주는 역할을 하게 됩니다.

한마디로 호스트OS가 점유하기 전에 vfio-pci드라이버가 장치를 갖고있다가 VM에다가 넘겨준다고 보시면 됩니다.
그럼으로써 vfio-pci가 넘겨준 장치를 받은 VM은 자신의 Kernel space에 알맞은 Driver(nvidia, nouveou등)를 설치하고,
그 Driver를 통해 PCI장치의 MMIO, DMA, Intrupt등을 직접 관리할 수 있게 되는 것이죠!
그래서 그림으로 정리하자면 다음과 같습니다.
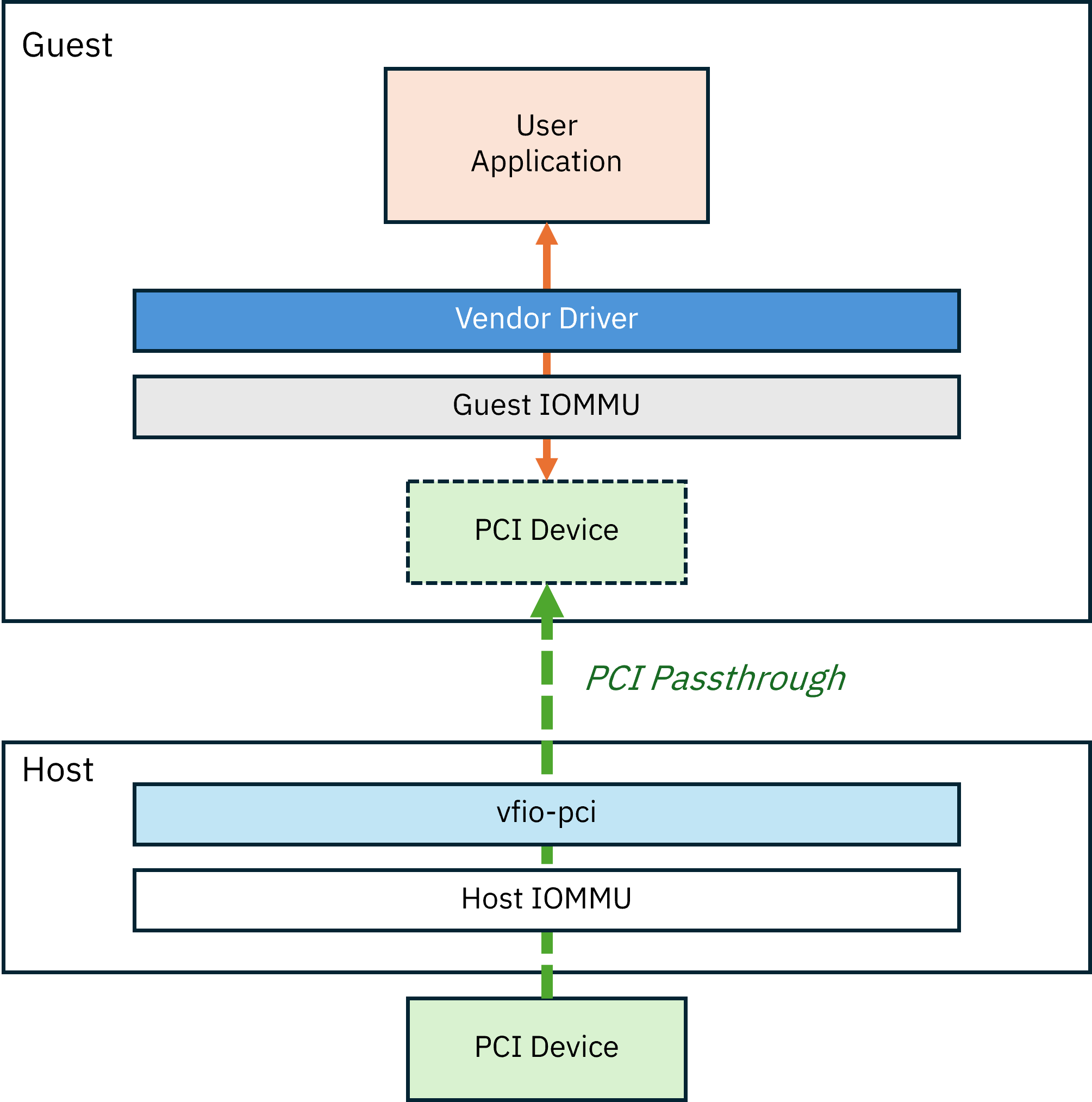
KVM에서 GPU Passthrough하기!Permalink
서론이 매우 길었습니다.. 그만큼 이해하고 있어야 하는게 많은 만큼 이 다음부터는 쉽게 따라하실 수 있을겁니다!
KVM이 설치되어있다는 가정하에 진행하겠습니다.
HOST 세팅Permalink
1. IOMMU 확인Permalink
먼저 IOMMU가 활성화되어있는지 확인합니다.
# dmesg | grep 'IOMMU enabled'
[ 5.182555] DMAR: IOMMU enabled
# sudo dmesg | grep -i -e DMAR -e IOMMU
...
[ 25.430640] pci 0000:ff:1e.6: Adding to iommu group 459
[ 25.430841] pci 0000:ff:1e.7: Adding to iommu group 459
[ 26.015882] DMAR: Intel(R) Virtualization Technology for Directed I/O
[ 27.338042] pci 10000:00:05.0: Adding to iommu group 45
[ 27.341951] pci 10000:00:07.0: Adding to iommu group 45
활성화 되어있지 않다면 grub 파일을 수정해줍니다.
GRUB_CMDLINE_LINUX_DEFAULT에 quiet splash intel_iommu=on을 추가해줍니다.
$ cat /etc/default/grub
# If you change this file, run 'update-grub' afterwards to update
# /boot/grub/grub.cfg.
# For full documentation of the options in this file, see:
# info -f grub -n 'Simple configuration'
GRUB_DEFAULT=0
GRUB_TIMEOUT_STYLE=hidden
GRUB_TIMEOUT=0
GRUB_DISTRIBUTOR=`( . /etc/os-release; echo ${NAME:-Ubuntu} ) 2>/dev/null || echo Ubuntu`
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash intel_iommu=on"
GRUB_CMDLINE_LINUX=""
$ sudo grub-mkconfig -o /boot/grub/grub.cfg
Sourcing file `/etc/default/grub'
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-6.8.0-55-generic
Found initrd image: /boot/initrd.img-6.8.0-55-generic
Found memtest86+ 64bit EFI image: /boot/memtest86+x64.efi
Warning: os-prober will not be executed to detect other bootable partitions.
Systems on them will not be added to the GRUB boot configuration.
Check GRUB_DISABLE_OS_PROBER documentation entry.
Adding boot menu entry for UEFI Firmware Settings ...
done
2. IOMMU 그룹 확인Permalink
연결하고자 하는 PCI장치의 IOMMU 그룹을 확인해줍니다.
$ for d in /sys/kernel/iommu_groups/*/devices/*; do n=${d#*/iommu_groups/*}; n=${n%%/*}; printf 'IOMMU Group %s ' "$n"; lspci -nns "${d##*/}"; done |grep NVIDIA
IOMMU Group 17 0000:41:00.0 3D controller [0302]: NVIDIA Corporation GH100 [H100 SXM5 80GB] [10de:2330] (rev a1)
IOMMU Group 18 0000:44:00.0 3D controller [0302]: NVIDIA Corporation GH100 [H100 SXM5 80GB] [10de:2330] (rev a1)
IOMMU Group 29 0000:11:00.0 3D controller [0302]: NVIDIA Corporation GH100 [H100 SXM5 80GB] [10de:2330] (rev a1)
IOMMU Group 29 0000:12:00.0 3D controller [0302]: NVIDIA Corporation GH100 [H100 SXM5 80GB] [10de:2330] (rev a1)
IOMMU Group 49 0000:bb:00.0 3D controller [0302]: NVIDIA Corporation GH100 [H100 SXM5 80GB] [10de:2330] (rev a1)
IOMMU Group 50 0000:be:00.0 3D controller [0302]: NVIDIA Corporation GH100 [H100 SXM5 80GB] [10de:2330] (rev a1)
IOMMU Group 58 0000:86:00.0 3D controller [0302]: NVIDIA Corporation GH100 [H100 SXM5 80GB] [10de:2330] (rev a1)
IOMMU Group 58 0000:87:00.0 3D controller [0302]: NVIDIA Corporation GH100 [H100 SXM5 80GB] [10de:2330] (rev a1)
IOMMU Group 86 0000:05:00.0 Bridge [0680]: NVIDIA Corporation GH100 [H100 NVSwitch] [10de:22a3] (rev a1)
IOMMU Group 87 0000:06:00.0 Bridge [0680]: NVIDIA Corporation GH100 [H100 NVSwitch] [10de:22a3] (rev a1)
IOMMU Group 88 0000:07:00.0 Bridge [0680]: NVIDIA Corporation GH100 [H100 NVSwitch] [10de:22a3] (rev a1)
IOMMU Group 89 0000:08:00.0 Bridge [0680]: NVIDIA Corporation GH100 [H100 NVSwitch] [10de:22a3] (rev a1)
IOMMU Group은 IOMMU가 관리하는 하나의 논리적 그룹을 뜻합니다.
하나의 그룹 안에 있는 장치들은 다같이 passthrough가 되고, 개별적으로 할당은 불가능합니다.
(스위치나 브릿지로 묶인 장치들은 하나의 그룹으로 묶일 수 있는데, 버그로인해서도 묶이게 될 수 있음… 이런 경우엔 PCIe ACS override 패치를 해서 강제로 분리 하면 된다고 하는데 나중에 해보게되면 작성하겠음)
3. 커널 드라이버 설정Permalink
이제 PCI장치 드라이버를 다른 드라이버가 점유하지 못하게 vfio-pci가 점유하도록 설정해주겠습니다.
nouveau나 snd_hda_intel같은 드라이버를 블랙리스트 처리,
위의 lspci결과로 나온 장치의 id값을 vfio-pci에 할당해줍니다.
$ cat /etc/modprobe.d/vfio.conf
blacklist nouveau
blacklist snd_hda_intel
options vfio-pci ids=10de:2330,10de:22a3
initramfs 업데이트:
$ sudo update-initramfs -u
장치 리부팅 후 lspci로 장치를 확인해보면 vfio-pci가 사용중이라고 나옵니다.
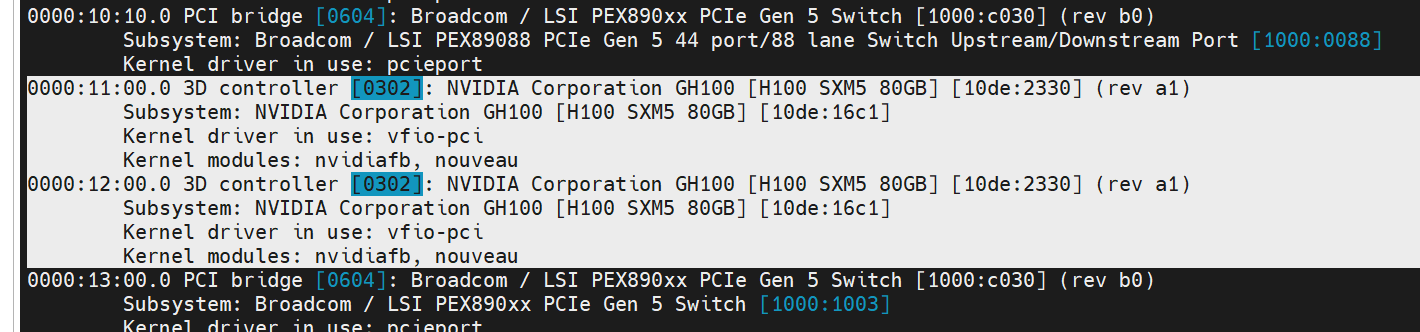
VM 세팅Permalink
4. VM만들기Permalink
그럼 이제 테스트 VM을 하나 만들어서 GPU passthrough가 잘 되었는지 확인해봅시다!
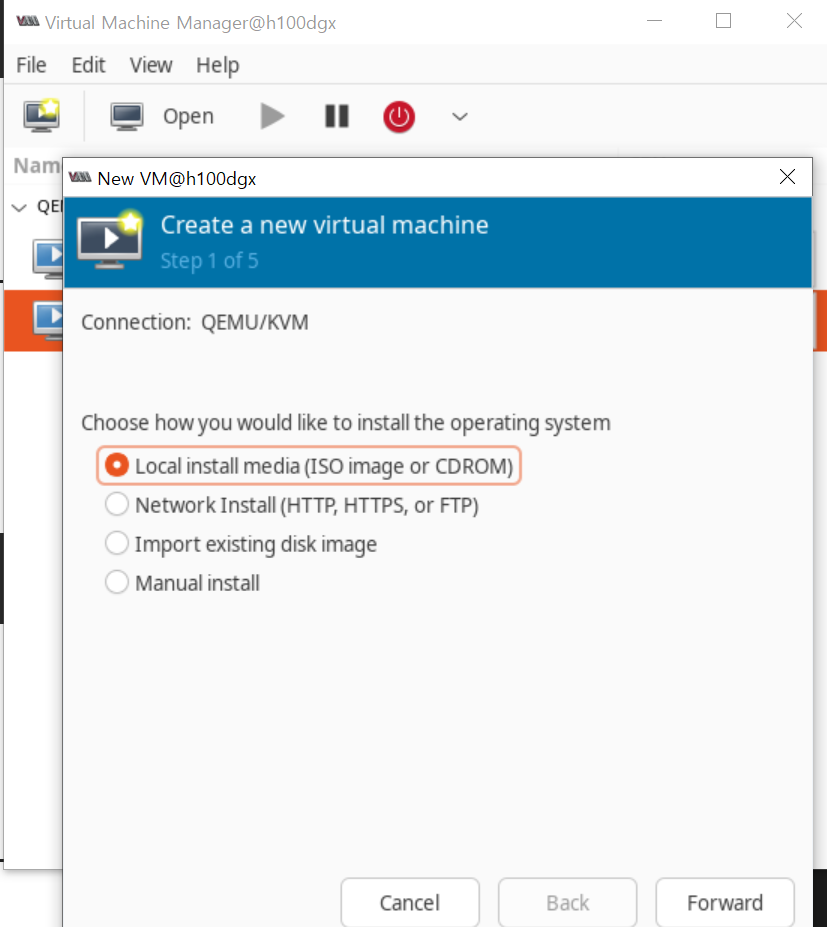
리소스와 네트워크 구성을 해주고, 마지막에 Customize Configuration before install을 체크해서 PCI장치들을 추가해줍니다.

(*중요) 반드시 Firmware는 secureboot가 꺼진 UEFI로 선택하여야 합니다.
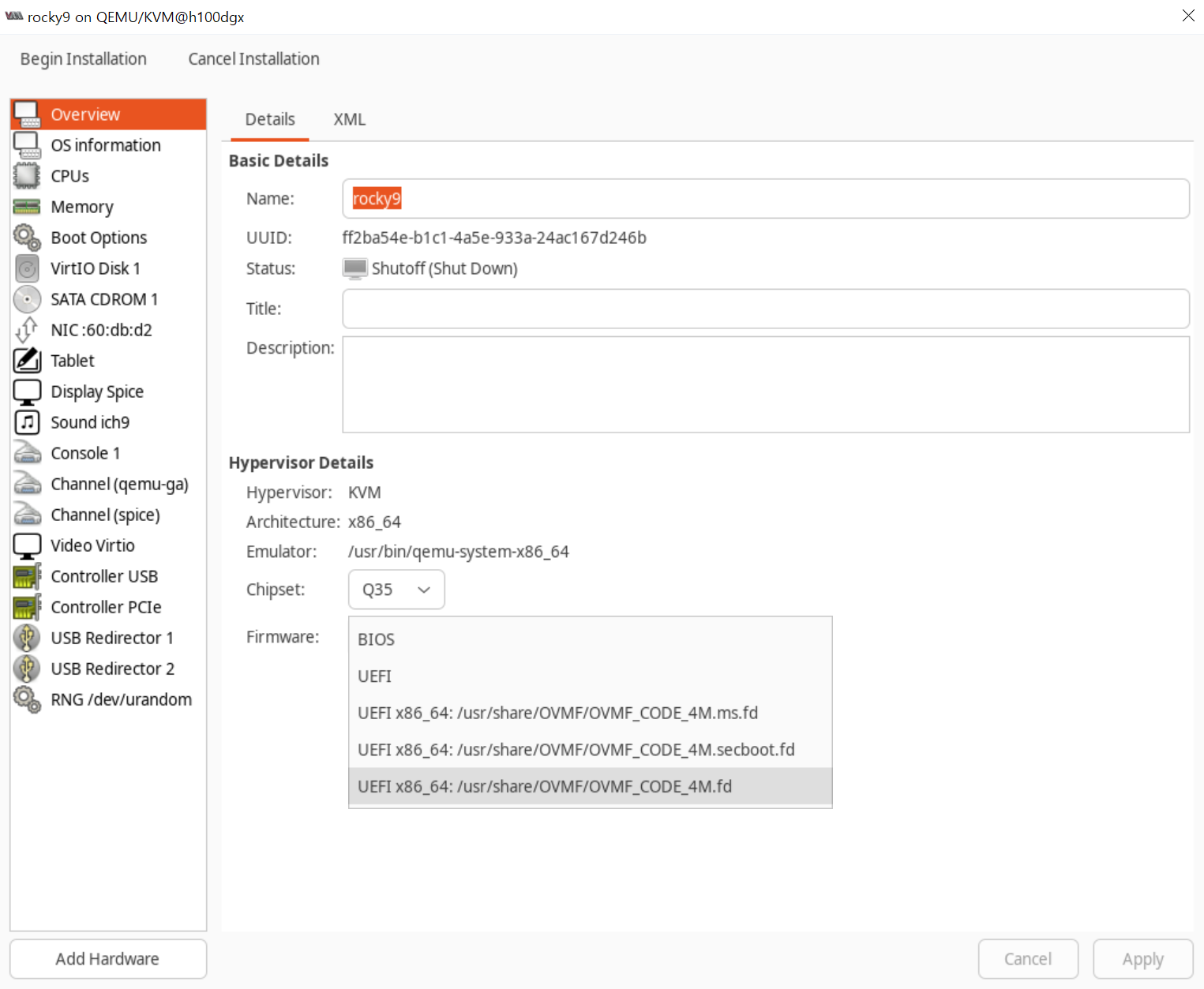
add hardware 눌러서 PCI장치를 추가해줍니다.
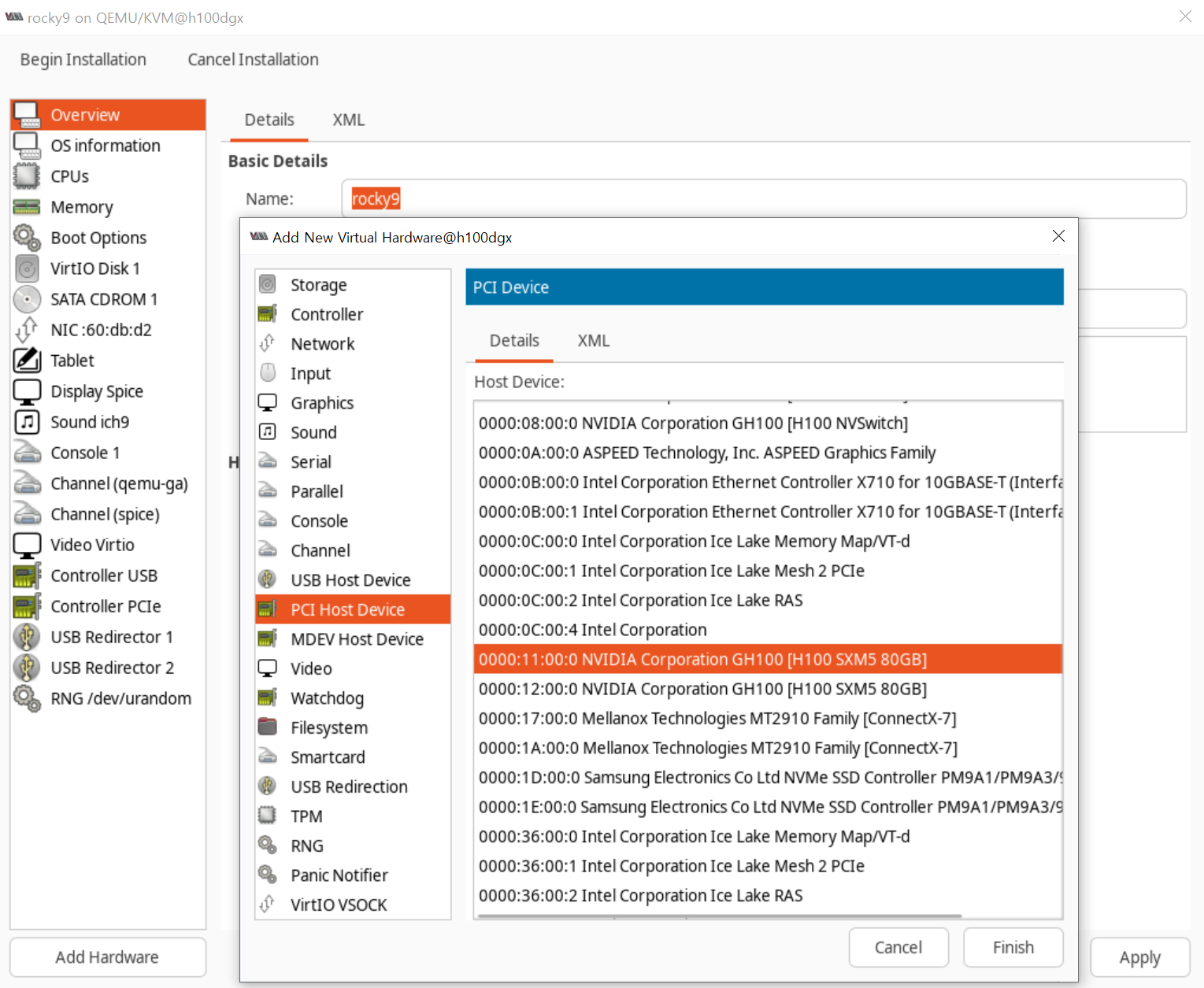
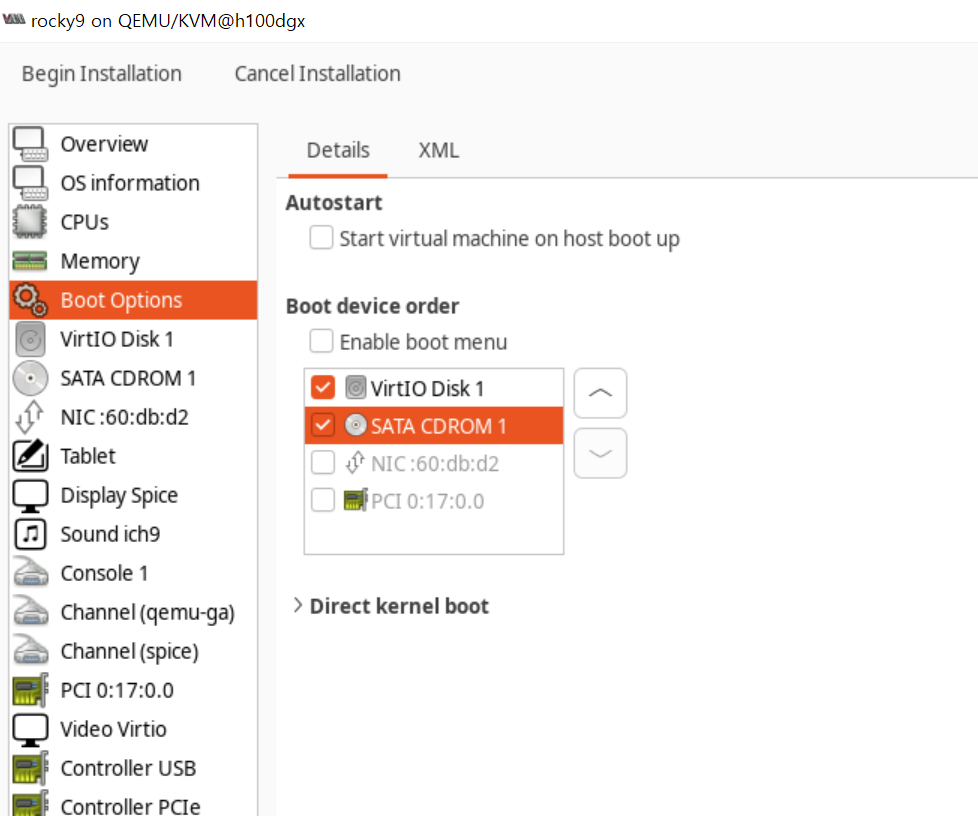
스타트!
PCI Passthrough된 GPU 테스트Permalink
OS가 설치가 잘 되었다면 이제 PCI Passthrough된 GPU를 테스트 해볼 차례입니다.
레포 설정을 해줍니다.
$ sudo dnf install epel-release
$ sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel9/x86_64/cuda-rhel9.repo
그 다음 현재 실행중인 커널에 맞는 개발 패키지와 헤더파일을 설치합니다.
$ sudo dnf install kernel-devel-$(uname -r) kernel-headers-$(uname -r)
만약 여기서 패키지가 없다고 뜬다면
dnf repoquery -q kernel-headers kernel-devel이 결과값이랑
uname -r결과값이랑 비교해보고, 다르다면 :$ dnf clean all한 뒤, reboot
다음으로 nvidia관련 드라이버를 설치해줍니다.
$sudo dnf install nvidia-driver nvidia-settings
$sudo dnf install cuda
제대로 설치되었는지 확인
$ rpm -qa | grep -i nvidia
nvidia-libXNVCtrl-570.124.06-1.el9.x86_64
nvidia-modprobe-570.124.06-1.el9.x86_64
nvidia-kmod-common-570.124.06-1.el9.noarch
kmod-nvidia-open-dkms-570.124.06-1.el9.noarch
libnvidia-ml-570.124.06-1.el9.x86_64
nvidia-driver-libs-570.124.06-1.el9.x86_64
nvidia-driver-570.124.06-1.el9.x86_64
nvidia-settings-570.124.06-1.el9.x86_64
libnvidia-cfg-570.124.06-1.el9.x86_64
nvidia-driver-cuda-libs-570.124.06-1.el9.x86_64
libnvidia-fbc-570.124.06-1.el9.x86_64
xorg-x11-nvidia-570.124.06-1.el9.x86_64
nvidia-xconfig-570.124.06-1.el9.x86_64
nvidia-persistenced-570.124.06-1.el9.x86_64
nvidia-driver-cuda-570.124.06-1.el9.x86_64
nvidia-open-570.124.06-1.el9.noarch
DKMS(Dynamic Kernel Module Support)로 현재 설치된 모듈 확인
$ dkms status
nvidia-open/570.124.06, 5.14.0-503.31.1.el9_5.x86_64, x86_64: installed
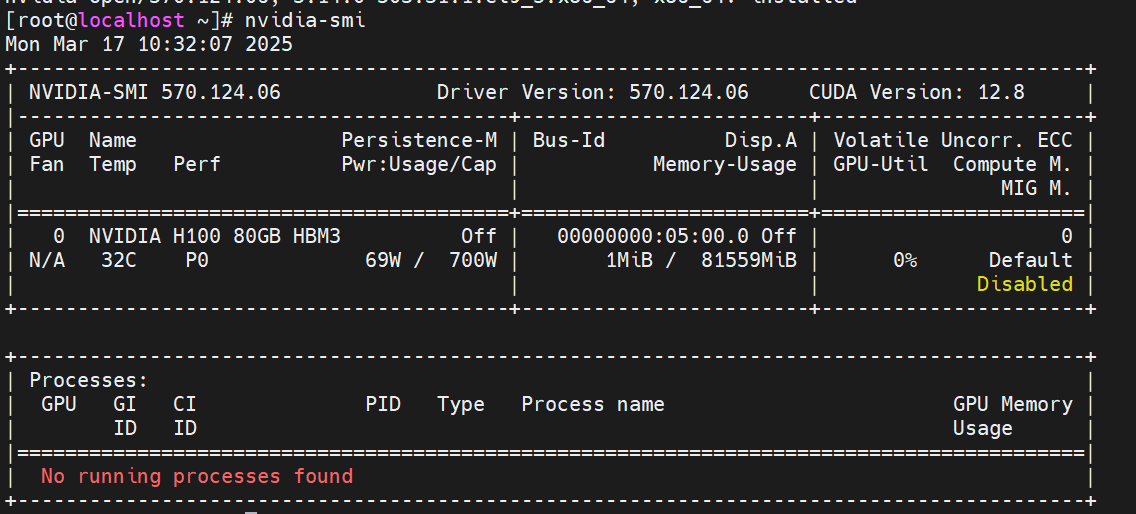
아래 명령어 입력 시 출력값이 없다면 성공
# sudo modprobe nvidia
구웃!
TroubleshootingPermalink
1. modprobe: ERROR: could not insert ‘nvidia’Permalink
SecureBoot가 활성화 되어있을 수 있음
아래 출력값대로 나오는지 확인해보기
# mokutil --sb-state
This system doesn't support Secure Boot
2. modprobe: FATAL: Module nvidia not found in directoryPermalink
현재 커널에 맞는 NVIDIA 드라이버가 설치되지 않은 경우.
먼저 DKMS로 설치된 모듈을 확인하고 현재 커널값과 비교
$ dkms status
nvidia-open/570.124.06: added
일치하지 않는다면 수동으로 nvidia driver 빌드
$ sudo dkms autoinstall
Sign command: /lib/modules/5.14.0-503.31.1.el9_5.x86_64/build/scripts/sign-file
Signing key: /var/lib/dkms/mok.key
Public certificate (MOK): /var/lib/dkms/mok.pub
Autoinstall of module nvidia-open/570.124.06 for kernel 5.14.0-503.31.1.el9_5.x86_64 (x86_64)
Cleaning build area...(bad exit status: 2)
Failed command:
make -C /lib/modules/5.14.0-503.31.1.el9_5.x86_64/build M=/var/lib/dkms/nvidia-open/570.124.06/build clean
Building module(s).................................................................. done.
Signing module /var/lib/dkms/nvidia-open/570.124.06/build/kernel-open/nvidia.ko
Signing module /var/lib/dkms/nvidia-open/570.124.06/build/kernel-open/nvidia-modeset.ko
Signing module /var/lib/dkms/nvidia-open/570.124.06/build/kernel-open/nvidia-drm.ko
Signing module /var/lib/dkms/nvidia-open/570.124.06/build/kernel-open/nvidia-uvm.ko
Signing module /var/lib/dkms/nvidia-open/570.124.06/build/kernel-open/nvidia-peermem.ko
Cleaning build area...(bad exit status: 2)
Failed command:
make -C /lib/modules/5.14.0-503.31.1.el9_5.x86_64/build M=/var/lib/dkms/nvidia-open/570.124.06/build clean
Installing /lib/modules/5.14.0-503.31.1.el9_5.x86_64/extra/nvidia.ko.xz
Installing /lib/modules/5.14.0-503.31.1.el9_5.x86_64/extra/nvidia-modeset.ko.xz
Installing /lib/modules/5.14.0-503.31.1.el9_5.x86_64/extra/nvidia-drm.ko.xz
Installing /lib/modules/5.14.0-503.31.1.el9_5.x86_64/extra/nvidia-uvm.ko.xz
Installing /lib/modules/5.14.0-503.31.1.el9_5.x86_64/extra/nvidia-peermem.ko.xz
Adding linked weak modules...
Running depmod.... done.
Autoinstall on 5.14.0-503.31.1.el9_5.x86_64 succeeded for module(s) nvidia-open.
$ dkms status
nvidia-open/570.124.06, 5.14.0-503.31.1.el9_5.x86_64, x86_64: installed
nvidia-smi했을 때 아래와 같이 에러가 출력된다면 현재 커널버전에 맞는 드라이버가 설치되어있는지 확인할 것.$ nvidia-smi NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest >NVIDIA driver is installed and running.
번외. Openshift에서 PCI passthrough된 GPU사용하기Permalink
위에서는 PCI Passthrough에 초점을 맞춰서 이야기를 진행했지만, 사실 GPU라는 녀석이 상당히 복잡한 장치입니다.
PCI direct connect가 되었는지, NVSwitch를 썼는지에 따라서도 어떤 드라이버가 추가로 필요한지도 달라지기 때문입니다.
(추후에 새로운 구성을 다뤄본다면 여기다가 업데이트 할 예정입니다 😎)
NVSwitch+GPUPermalink
이 파트에서 다룰 내용은 NVSwitch를 사용한 GPU Passthrough에 대해서 입니다.
NVSwitch를 사용한 GPU는 fabric manager라는 드라이버가 반드시 필요한데요, 이게 없다면 GPU는 보이지만 사용할 수 없는 상태가 되고 맙니다.
# cuda-validator에서 확인 가능
Failed to allocate device vector A (error code system not yet initialized)!
[Vector addition of 50000 elements]
NVSwitch를 사용한 GPU라면 반드시 NVSwitch까지 같이 PCI Passthrough로 묶어주어 VM에서 NVSwitch가 보이게 만들어 줘야 합니다.
이 이후는 GPU Operator가 알아서 처리해주니 편하게 사용이 가능합니다.
완료!
$ oc get pod -n nvidia-gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-56hhm 1/1 Running 0 3m25s
gpu-operator-fb748c8d8-dpxqb 1/1 Running 0 62m
nvidia-container-toolkit-daemonset-2ftj6 1/1 Running 0 3m25s
nvidia-cuda-validator-s46h5 0/1 Completed 0 115s
nvidia-dcgm-exporter-zhkcl 1/1 Running 0 3m25s
nvidia-dcgm-sn7nv 1/1 Running 0 3m25s
nvidia-device-plugin-daemonset-tdmmp 1/1 Running 0 3m25s
nvidia-driver-daemonset-417.94.202503060903-0-f7xv9 2/2 Running 2 60m
nvidia-mig-manager-9g72n 1/1 Running 0 3m24s
nvidia-node-status-exporter-lgqr7 1/1 Running 1 60m
nvidia-operator-validator-7gqzd 1/1 Running 0 3m25s
댓글남기기