
호다닥 톺아보는 Kafka
Overview
예를 들어서 특정 서비스를 제공하는 app이 있다고 가정하고 그 app의 로그를 받아서 처리하는 또다른 app이 있다고 가정해봅시다.
대충 아래와 같은 모습이 되겠습니다.
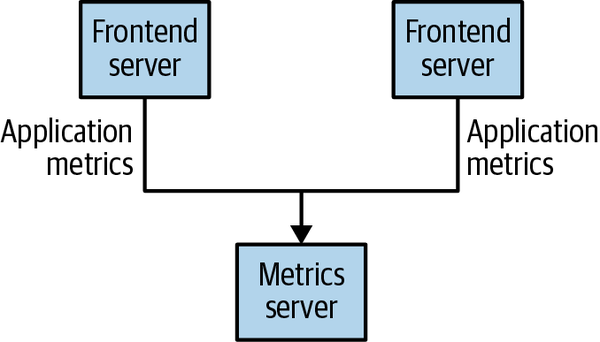
하지만 점점 더 복잡한 서비스에서는 어떻게 될까요?
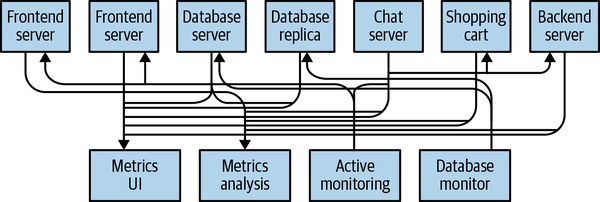
위와 같이 수많은 소스 application과 타겟 application들이 직접적으로 통신하게 되면서 서비스 구조도 복잡해지고, 통신 프로토콜의 파편화가 심해지게 됩니다.
이렇게 되면 배포나 장애에 대응하기 어려워지고, 유지보수가 힘들어진다는 단점이 있습니다.
Apache Kafka란?
탄생
소셜 네트워크 앱중 하나인 “LinkedIn“의 개발자들도 이와 같은 문제를 갖고 있었습니다.
2011년 LinkedIn은 이런 복잡함을 해결하고자 소스app과 타겟app의 커플링을 낮게 하려하였고 분산메시징시스템인 Apache Kafka를 개발하였습니다.
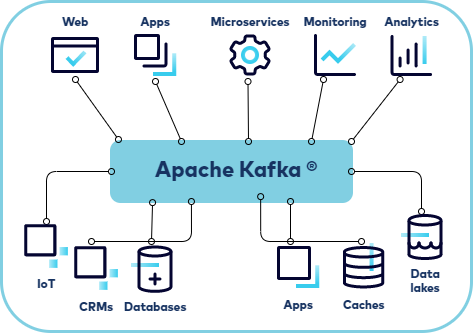
그림에서 확인할 수 있다시피, Kafka는 데이터 파이프라인을 파편화하지않고 모든 이벤트/데이터의 흐름을 중앙집중화 시켰습니다.
그래서 모든 application은 다른 app이아니라 kafka만 바라보면 되는 구조가 되는 것이죠.
Kafka는 2011년 오픈소스로 공개되었고, 2012년 10월 Apache 인큐베이터를 종료한 상태입니다.
현재 Kafka개발을 주도하던 Jay Kreps를 비롯한 일부 엔지니어들은 Confluent라는 회사를 설립하여 Kafka관련 일들을 하고 있다고 합니다.
여담으로 Kafka는 유명한 작가인 프란츠 카프카(Franz Kafka)에서 따왔다고하고, 실제 구조나 기능과는 크게 관계가 없다고 합니다.
“I thought that since Kafka was a system optimized for writing, using a writer’s name would make sense. I had taken a lot of lit classes in college and liked Franz Kafka. Plus the name sounded cool for an open source project.
So basically there is not much of a relationship.”
Components
그럼 Kafka가 어떤 구조로 이뤄져있는지 살펴보도록 하겠습니다.
Topic
Kafka는 이벤트 스트리밍 플랫폼입니다. Kafka에 전달되는 메세지 스트림의 추상화된 개념을 Topic이라고 부릅니다.

이벤트를 만들어내는 Producer가 어떤 Topic에 데이터를 적재할건지, Consumer는 어떤 Topic에서 데이터를 읽을건지(구독할건지) 정하게 됩니다.
Topic은 여러개 생성할 수 있으며, 각각의 메세지를 목적에 맞게 구분할 때 사용합니다.
Partition
각 Topic은 내부에 더 세분화된 단위인 Partition을 가지고 있습니다.
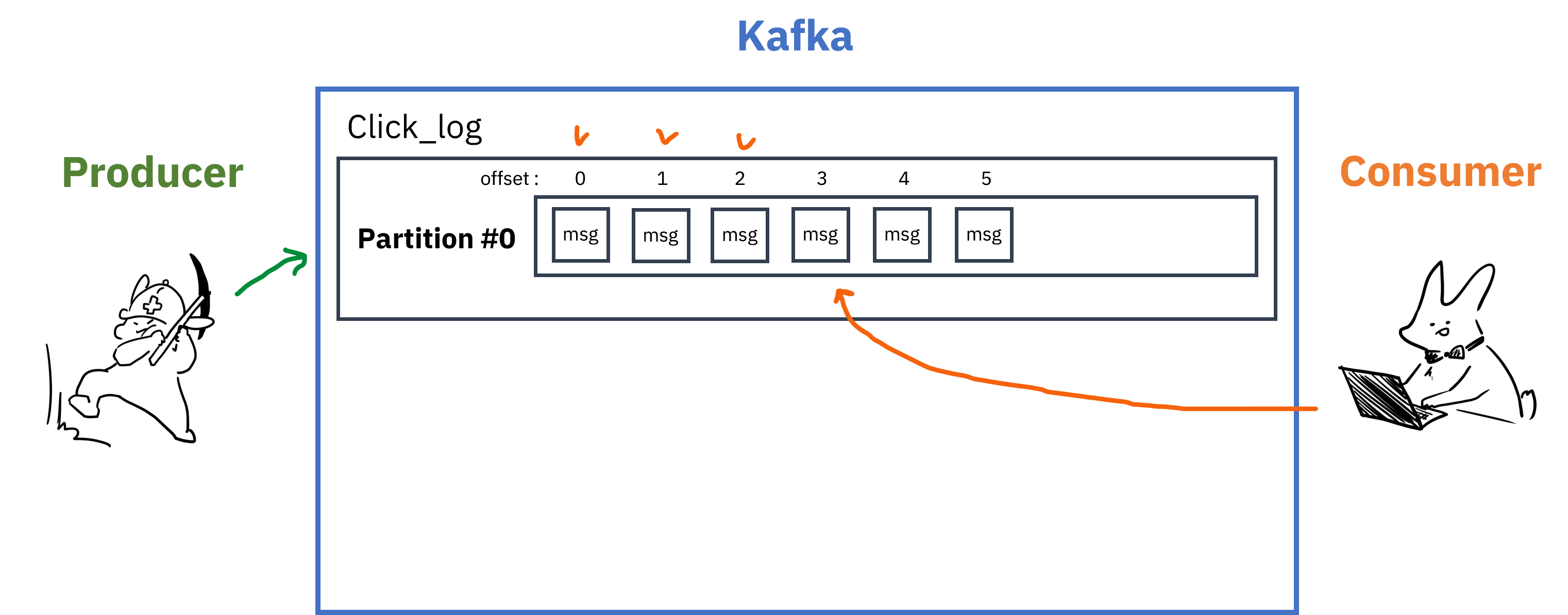
- 메세지가 들어오면 순차적으로 추가되며, Consumer가 메세지를 읽을 때에는 Queue의 선입선출(FIFO)과 비슷하게 오래된 메세지부터 읽게됨
- Queue와 다른 점은 레코드를 읽어도 사라지지 않는다는 점
- 이게 가능한 이유는 Queue가 아닌 실제 파일시스템에 데이터가 저장되기 때문
- 때문에 Consumer처리가 늦거나 Kafka클러스터에 문제가 생겨도 메세지 손실이 발생하지 않음
- Consumer가 Partition의 레코드를 읽을 때에는
offset이라는 저장위치를 기억하고 있어서 문제가 생겨도 읽던 위치부터 다시 읽기 가능 - Partition에는 여러 Consumer 그룹이 붙을 수 있고, 그룹이 다르고 auto.offset.reset=earlist 일 경우 각 Consumer 그룹은 0번 레코드부터 읽기 시작함
Topic은 하나 이상의 Partition을 가질 수 있는데, 여러개의 Partition을 가지고 있는 경우를 생각해보겠습니다.

- 데이터를 적재할 시, 키값을 지정해주어 특정 Partition에만 데이터 적재 가능
- 키값을 지정해주지 않았을 경우, Round-robin방식으로 데이터 적재
- Partition을 늘리는 것은 가능하지만 줄일수는 없음 (없애려면 Topic 전체를 삭제)
- Partition을 늘리면 Consumer를 늘려서 데이터 처리를 분산할 수 있음
- Partitioning을 통한 분산 처리로, 데이터의 순서가 보장되면서 성능을 향상시킬 수 있음
예를 들어서 4개의 Producer에서 1개의 Partiton에 전송되는데 1초가 걸리는 메세지를 보냈다고 생각해봅시다.
MQ시스템 하에서는, 반드시 메세지의 순서가 보장되어야하기 때문에 1초가 걸린다고 해도 이를 모두 처리하는데 4초의 시간이 소요되게 됩니다.
결국 순서를 지키며 병렬적으로 메세지를 처리하기 위해서는 하나의 Topic안에 여러개의 Partition을 둠으로써 처리할 수 있습니다.
즉, 4개의 Producer가 메세지를 4개의 Partition에다 보낸다면 4초가아닌, 1초만 소요되는 것입니다.
- 다만 Partition을 늘리는 것이 능사는 아님
- 리소스 낭비 : 각 Partition은 Broker의 directory와 매핑, 저장되는 데이터마다
Index,실제데이터가 저장됨 - 장애복구 시간 증가 : replication을 설정했을 경우, Broker에 장애가 발생하면 각 partition에 대한 리더를 선출해야하므로 partition개수가 많으면 그만큼 시간소요
- 리소스 낭비 : 각 Partition은 Broker의 directory와 매핑, 저장되는 데이터마다
Partition에 저장된 데이터는 삭제할 시점을 설정해줄 수 있습니다.
log.retention.ms: 최대 record 보존시간log.retention.byte: 최대 record 보존크기(byte)
Broker
Broker는 Kafka가 설치되어있는 서버의 단위입니다.
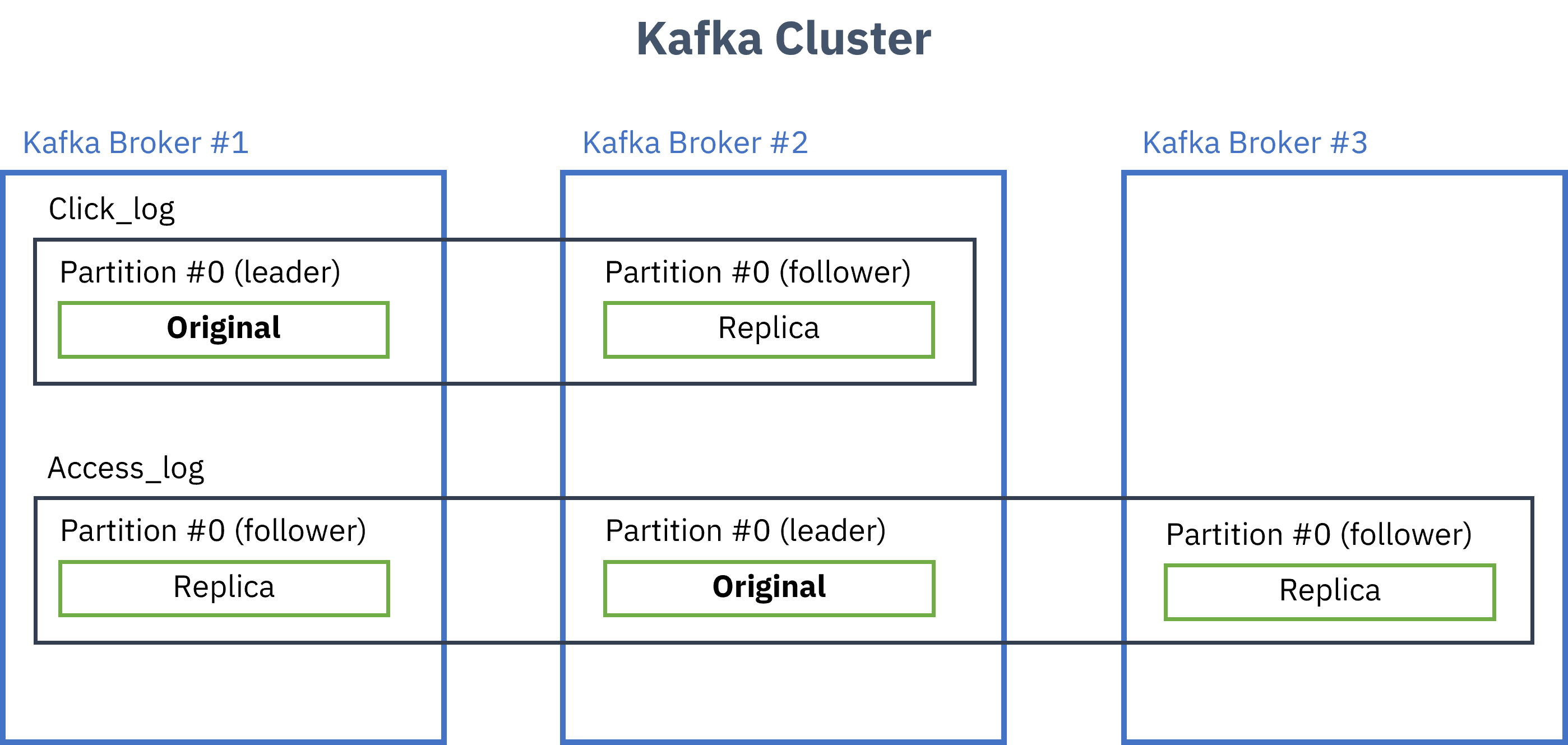
- 보통 3개 이상 권장
- replication을 지정해주면 그 수만큼 원본+복제본 생성
- 원본은 leader partition, 복제본은 follower partition으로 부르며 이를 합쳐서 ISR(In Sync Replica)라고 부름
- leader가 정상적으로 동작하지 않을 경우 follower가 leader의 역할을 대신함
- Producer(kafka-client)는 각 Topic의 leader partition에 데이터를 전송,
ack값을 설정해서 데이터 복제에 대한 commit가능0: leader partition에 데이터 전송하고 응답안받음 (보내는 사이에 데이터유실가능성 있음)1: leader partition에 데이터 전송하고 응답받음 (leader가 받고 follower들한테 복사하기전에 leader가 죽으면 데이터 유실가능성 있음)all: 모든 replica에 데이터 복제 후 응답받음(각 broker들한테서 응답받음, 데이터유실X, 속도느림)
- replication이 많아질수록 고가용성이 높아지지만 저장공간도 많이 필요하고(n배), Broker 리소스도 많이 사용하게 됨(replication상태체크)
Producer
Producer는 데이터를 만들어내고 Kafka Topic에 데이터를 적재시키는 주체입니다.
- 특정 Topic으로 데이터를 publish
- kafka broker로 데이터를 전송할때 성공여부를 알려주고, 실패하면 재시도 가능
Consumer
Consumer는 Kafka Topic에서 데이터를 읽어오는 주체입니다.
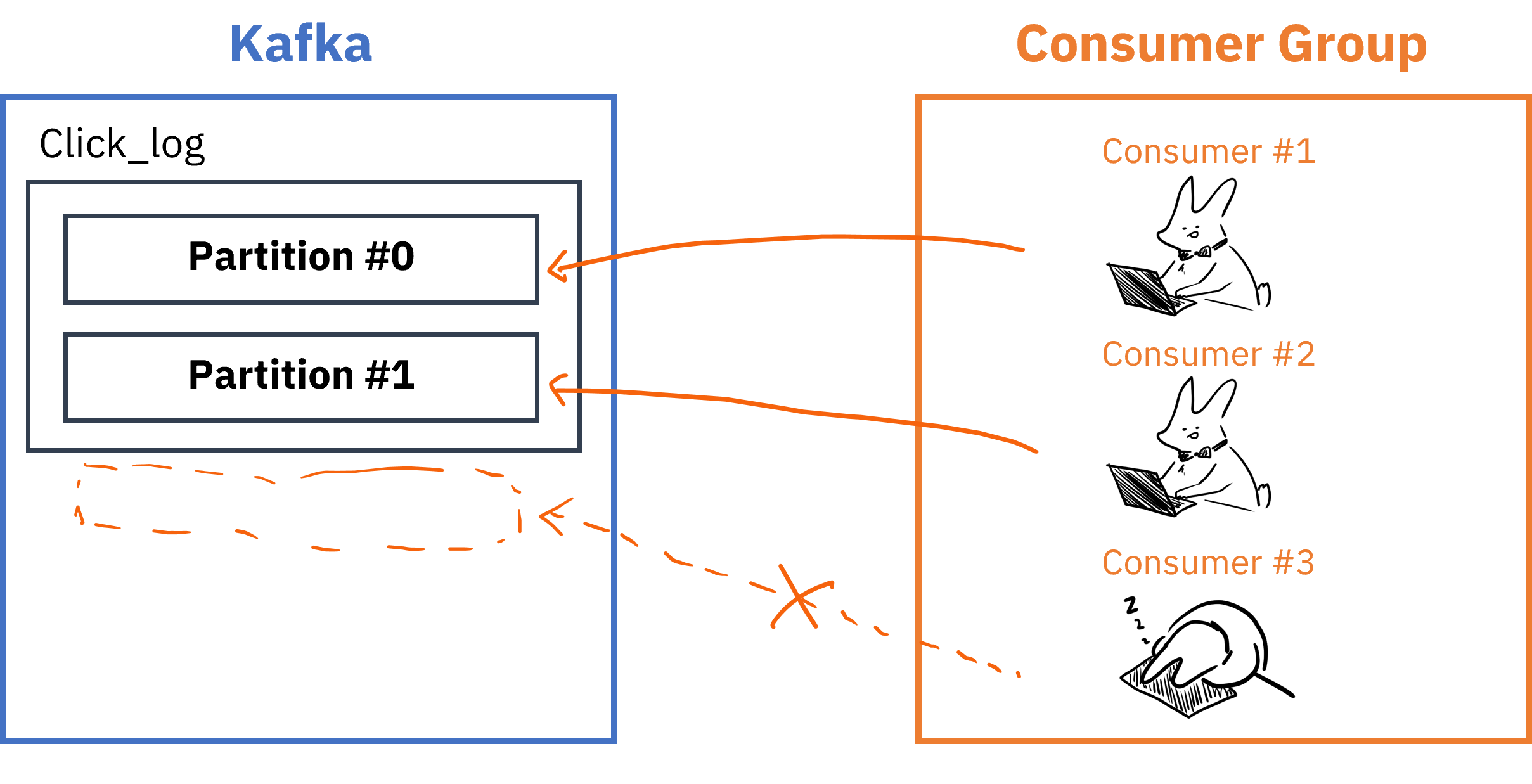
- Consumer가 데이터를 읽은 지표인
offset정보는__consumer_offset토픽에 저장되어 Consumer에 장애가 발생해도 원래 위치부터 읽기 시작 가능 - Topic의 Partition과 Consumer그룹은 1:N매칭으로, 동일 그룹내 한개의 컨슈머만 연결가능 -> 메세지가 순서대로 처리되도록 보장
- Consumer 그룹 내 Consumer 개수는 Partition개수보다 적거나 같아야 함
Consumer Group이 여러개 존재할 경우,
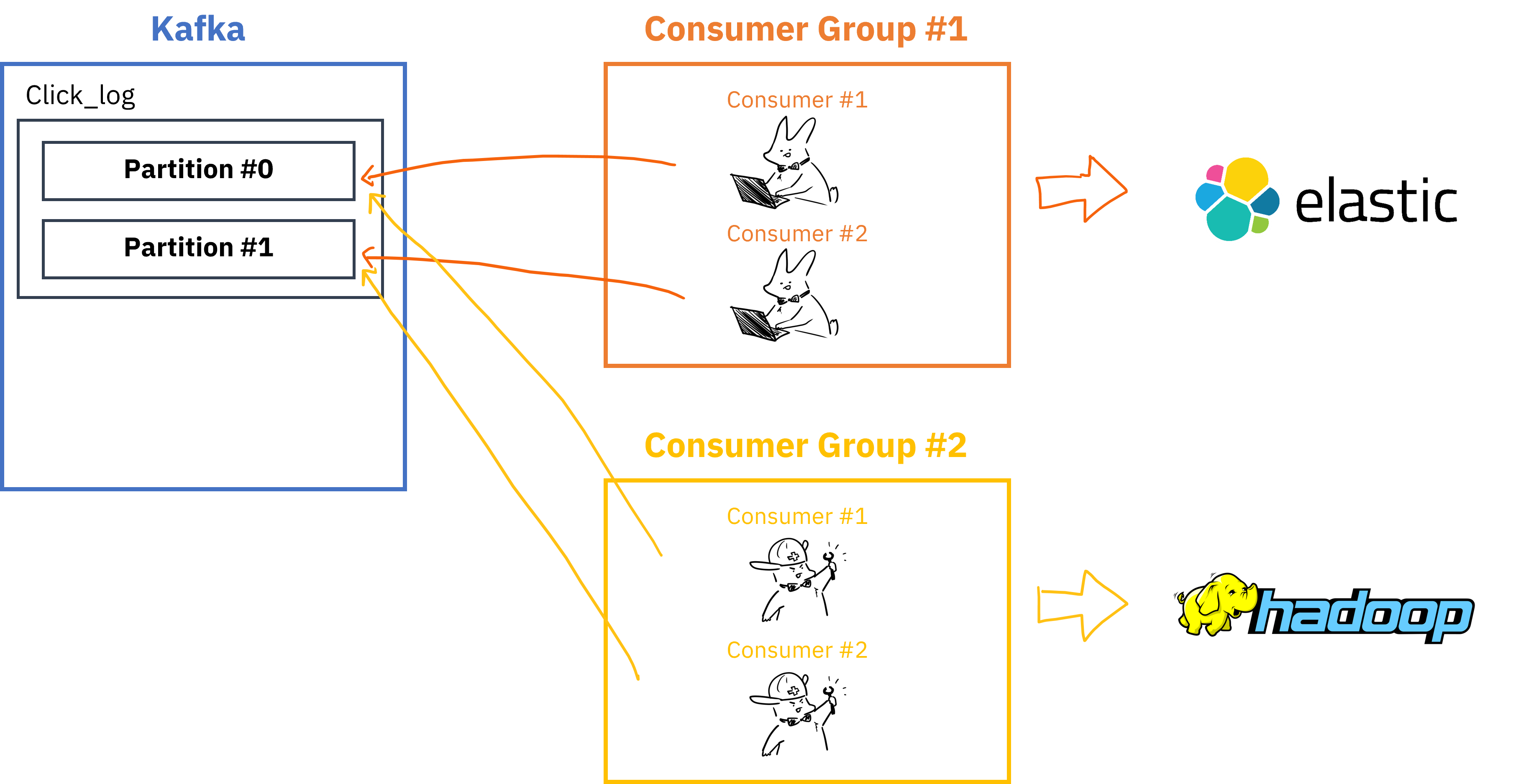
- 여러 Consumer Group을 통해 병렬처리 가능
__consumer_offset토픽에는 Consumer group별/토픽별로 offset을 나눠서 저장하기 때문에 Consumer group이 다르면 각자의 그룹은 서로 영향을 끼치지않음
Kafka 특징
1. 높은 처리량 (High throughput)
- batch기능을 제공하여 짧은 시간안에 대량의 데이터를 consumer까지 전달가능
- 대용량 실시간 로그처리에 특화
2. 확장성 (Scalability), 고가용성(High Availability)
- 쉽게 Broker, Partition, Consumer Group 추가 가능
- Broker 확장
- 복제본(replication)을 늘려서 데이터 유실 방지
- 너무 늘렸을 시, 성능 저하의 이슈 + 높은 리소스 사용량
- Partition 확장
- 데이터 처리 분산
- 늘렸다가 다시 줄이는 것이 어려움 (Topic전체 삭제해야함)
- 리소스낭비 + 장애 복구 시간 증가
- Consumer Group 확장
- 병렬처리
- Broker 확장
- Topic 내 Partition 복제 가능
- 복제 수만큼 Partition의 복제본이 각 Broker에 생김
3. 낮은 의존도
- 소스와 타겟 어플리케이션의 의존도를 낮춰줌
- 여러 Producer, Consumer가 상호 간섭 없이 메세지 쓰고 읽기 가능
- Broker는 Consumer와 Partition간 매핑 관리만 집중
- 메세지 필터, 재전송과 같은 일들은 Producer와 Consumer에 위임
4. 이벤트 보존성
- 한번 이벤트가 Partition에 저장되면 정해진 retension 기간동안 보존
- Consumer가 항상 떠있지 않아도,
offset을 통한 읽던 위치 기억 - Partition의 이벤트들은 파일시스템에 저장됨
5. Page Cache & Zero Copy
-Page Cache : 처리한 데이터를 RAM에 올려서 데이터에 대한 접근이 발생할 때 Disk IO를 발생시키지 않고 처리할 수 있는 기법
-Zero Copy : 일반적으로는 Disk에서 데이터를 읽고 RAM에 올리고 네트워크 전송을 하지만, Zero Copy는 Disk에서 데이터를 읽음과 동시에 네트워크 전송을 함
- Producer가 Broker에 데이터를 적재할 때 즉시 Disk에 파일을 저장하는 대신
Page Cache에 저장 -> 일정 시간 후 Disk에 파일 쓰기 - Consumer가 데이터를 Broker에서 읽어갈 때 데이터를
Page Cache에 올려두어 동일 데이터를 다른 Consumer가 읽을 때 빠르게 읽을 수 있게 함 - 일반적으로는 Disk IO시간이 많이 소요되기때문에 Disk기반이라 하면 느리게 보일 수 있지만 위와 같은 처리를 통해 빠른 속도를 유지
참고링크
- Kafka documentation
- Confluent Developer - Design Overview
- Kafka: The Definitive Guide, 2nd Edition
- 데브원영 - 빅데이터의 기본 💁♂️ 아파치 카프카! 개요 및 설명
- ooeunz - 데이터 모델: topic, partition, replication
- skyer9 - Kafka 는 왜 빠를까?
- TAS - 페이지 캐시와 버퍼 캐시, 그리고 리눅스 파일 시스템
댓글남기기