
ODF Resource Customization
Overview
OpenShift에서 가장 쉽게 스토리지를 구성할 수 있는 방법인 OpenShift Data Foundation 를 사용하게 되면 Ceph Cluster를 통해 File, Block, Object 스토리지를 사용할 수 있게 됩니다.
Ceph는 오픈소스 Software Defined Storage 솔루션 중 하나로, 여러 스토리지를 하나로 묶어 하나의 스토리지처럼 사용할 수 있게 해줍니다.
이 Ceph를 Kubernetes위에 올리려면 Rook이라는 도구를 사용해 올릴 수 있고 이 문서에서 자세히 다루진 않겠습니다.

크게보면 RADOS라는 스토리지 노드 위에 LIBRADOS라는 RADOS의 라이브러리가 있고, Object Storage서비스를 제공하는 RADOSGW(rgw), Block Device(rbd), File system(cephfs)으로 구성되어 있습니다.
여담으로 RADOS는 paxos알고리즘을 기반으로 만들어졌다고 한다!
RADOS: A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters -4.1 Paxos Service
그리고 이런 서비스들을 제공하는 ceph cluster는 클러스터 관리를 위한 4개의 컴포넌트를 갖고 있습니다.

- OSD 데몬: 데이터를 저장하고 복제, 분산하는 역할
- Monitor : 클러스터상태를 체크
- Manager : 프로세스 메타데이터 및 호스트 메타데이터에 대한 정보 유지
- MDS(Metadata Service) : CephFS에서 사용하는 메타데이터 저장
대략 구성 요소는 4개 정도고, 단순히 스토리지만 사용하는데에는 이런 자세한 내용까지는 알 필요가 없지만…
이번에 문제가 되었던 부분은 저 데몬들이 Resource Request를 엄청나게 잡아먹는다는 것입니다.
기본적으로 Kubernetes는 클러스터가 가용가능한 리소스들의 총 합을 내부에 가지고 있고, 각 pod가 resource request를 요청할때마다 resource들의 일부분을 내주는데
이때문에 실제 usage는 적어도 resource가 부족해서 pod를 못띄운다는 경고가 뜨게 됩니다.
특히 Operator처럼 필요한 Resource의 limit과 request가 이미 정해져서 돌아가는 경우에는, 아무생각없이 Operator들을 돌렸다간 금방 Cluster resource가 없어지는 모습을 볼 수 있을겁니다.
제 경우에는 worker노드가 16개인 클러스터에 ODF를 올렸었는데, OSD pod들이 cpu를 2코어씩 가져가니까 순식간에 CPU Request Commitment가 80%까지 차버렸었습니다…
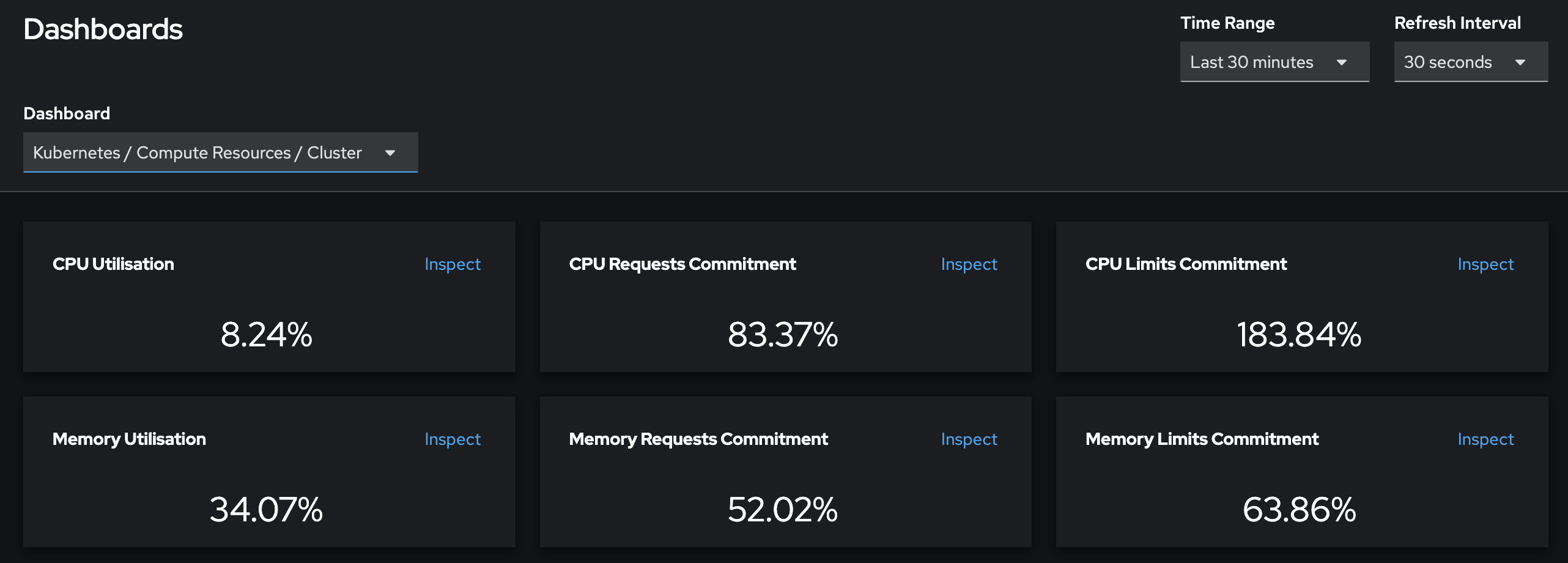
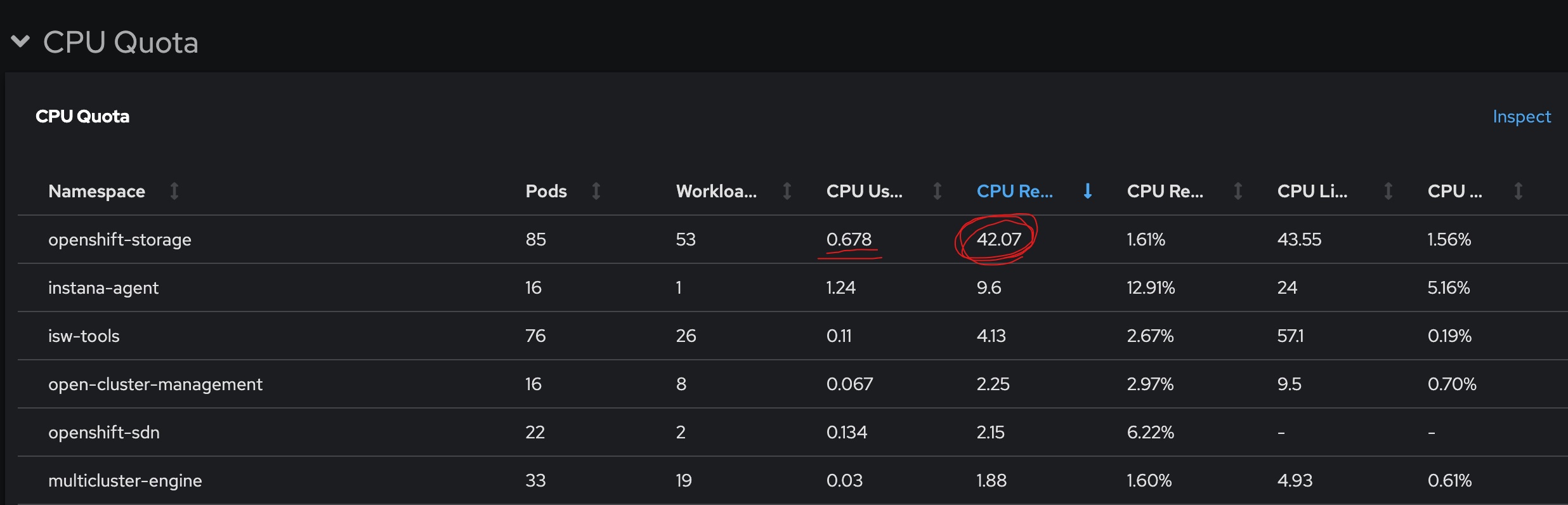
사용률은 1core도안되는데 request만 42core인 기묘한 상황
이번 문서에서는 ODF의 ceph cluster의 각 컴포넌트의 resource를 조정하는 방법에 대해서 써보도록 하겠습니다.
물론 Operator가 ODS에 2코어씩 준 이유는 최소한의 성능을 보장하기 위한 안전장치일겁니다.
일반적인 경우엔 권장 사항을 따르는것이 맞지만 저처럼 스토리지 성능은 크게 중요하지 않고, 다른 목적이 있는 경우 resource request양을 조정할 필요가 있습니다.
StorageCluster
반드시 클러스터 목적에 맞춰서 resource를 조정하시기 바랍니다.
참고 : Chapter 11. Changing resources for the OpenShift Container Storage components
ODF Operator를 살펴보면 StorageSystem이라는 녀석이 있습니다.
이게 최상단에서 클러스터의 설정들을 관리하는 녀석이라고 생각하시면 됩니다.

yaml을 까보면 StorageSystem이 관리하고 있는 instance들의 정보만 나오지 막상 수정할 수 있는 부분은 보이지 않습니다.
그래서 StorageSystem이 관리하는 instance중 하나인 StorageCluster로 내려갑니다.
yaml을 열어보면 storageCluster에서 관리하는 노드들, instance들, 각종 ceph, noobaa설정이 보입니다.
익숙하지 않다면 storageCluster의 스키마중에서 어떤 항목이 각 컴포턴트와 연관되어있는지 알기 힘들겁니다.
storageCluster의 yaml파일을 조금 밑으로 내려보면 status.relatedObjects에 현재 ODF의 CephCluster와 NooBaa의 설정을 볼 수 있는 객체의 이름이 적혀있습니다.
...
status:
relatedObjects:
- apiVersion: ceph.rook.io/v1
kind: CephCluster
name: ocs-storagecluster-cephcluster
namespace: openshift-storage
- apiVersion: noobaa.io/v1alpha1
kind: NooBaa
name: noobaa
namespace: openshift-storage
...
일단 CephCluster를 검색해보면 현재 ODF에서 돌고있는 CephCluster의 yaml configuration을 볼 수 있습니다.
여기서 설정값을 참고해서 상위 객체인 storageCluster의 설정을 바꿔주도록 합니다.
ODF의 CephCluster는 Rook의 CephCluster CRD를 따르고 있으니 아래 문서를 참고해도 됩니다.
ROOK : CephCluster CRD
mds, mgr, mon, rgw
spec.resources 하위에 명시해줍니다.
spec:
...
resources:
mds:
limits:
cpu: 300m
memory: 2Gi
requests:
cpu: 300m
memory: 2Gi
mgr:
limits:
cpu: 300m
memory: 2Gi
requests:
cpu: 300m
memory: 2Gi
...
osd
spec.storageDeviceSets.resources 하위에 명시해줍니다.
spec:
storageDeviceSets:
- config: {}
...
name: ocs-deviceset-cekr-stg
replica: 1
resources:
limits:
cpu: 300m
memory: 2Gi
requests:
cpu: 300m
memory: 2Gi
⚠ 반드시 클러스터 목적에 맞춰 Resource를 할당해주세요! ⚠
결과
이렇게 설정을 변경하고 몇 분 기다리면 바꾼 설정값대로 pod들이 다시 기동하고 클러스터의 CPU Request Commitment는 납득가능한 수준으로 떨어진 것을 확인할 수 있었습니다.
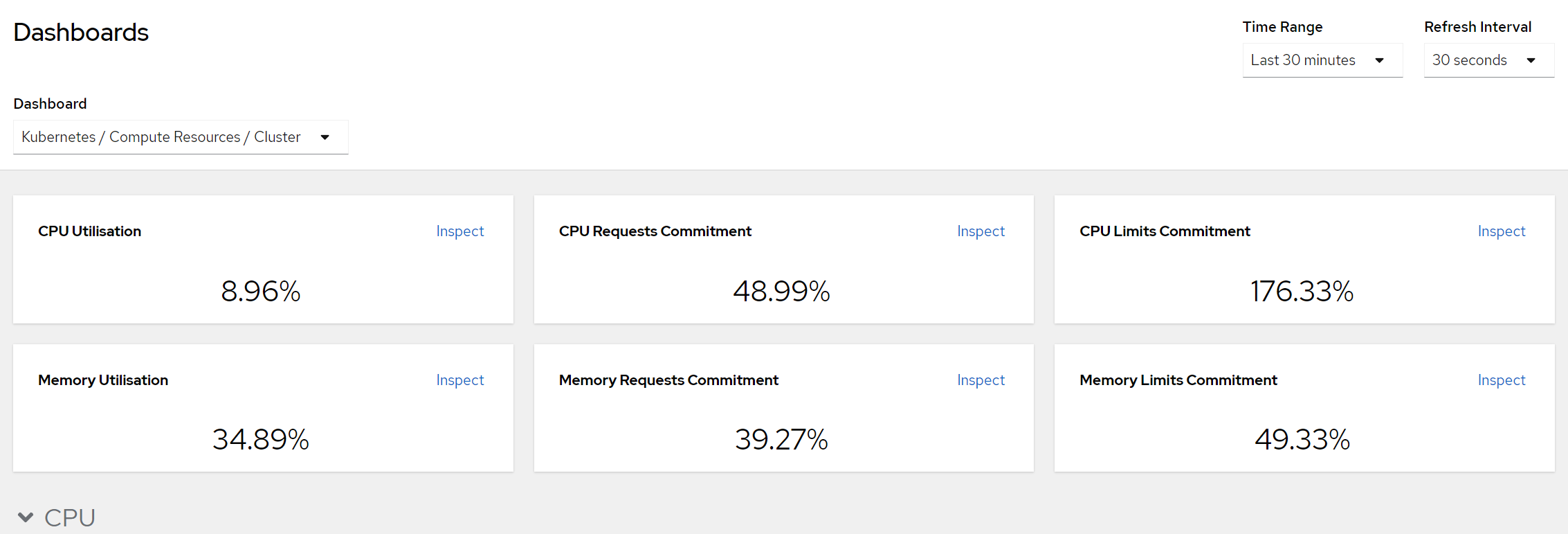
운영하다가 설정해준 request/limit값이 사용량에 비해 낮다고 생각이 들면 다시 조정해주면 됩니다!
물론 테스트 환경이니 이렇게 늘렸다 줄였다 자유롭게 할 수 있는것이겠지만, 실제 적용할 때에는 Dashboard의 면밀한 검토와 논의가 필요할 것 같습니다.
끝!
댓글남기기